Automatically generated by ./gen_a_and_at.sh on Wed Jun 8 15:54:33 PDT 2005.
|
Defines |
|
#define | REGISTER register |
| | Real-valued, so use explicit 'register' keyword.
|
|
#define | MBCSR_MatMultAndMatMult_v1_aX_b1_xs1_ysX_oX_z1_ws1_zsX MANGLE_MOD_(MBCSR_MatMultAndMatMult_v1_aX_b1_xs1_ysX_oX_z1_ws1_zsX_4x2) |
| | Mangled name for MBCSR_MatMultAndMatMult_v1_aX_b1_xs1_ysX_oX_z1_ws1_zsX.
|
|
#define | MBCSR_MatMultAndMatMult_v1_aX_b1_xsX_ysX_oX_z1_wsX_zsX MANGLE_MOD_(MBCSR_MatMultAndMatMult_v1_aX_b1_xsX_ysX_oX_z1_wsX_zsX_4x2) |
| | Mangled name for MBCSR_MatMultAndMatMult_v1_aX_b1_xsX_ysX_oX_z1_wsX_zsX.
|
|
#define | MBCSR_MatMultAndMatTransMult_v1_aX_b1_xs1_ysX_oX_z1_wsX_zs1 MANGLE_MOD_(MBCSR_MatMultAndMatTransMult_v1_aX_b1_xs1_ysX_oX_z1_wsX_zs1_4x2) |
| | Mangled name for MBCSR_MatMultAndMatTransMult_v1_aX_b1_xs1_ysX_oX_z1_wsX_zs1.
|
|
#define | MBCSR_MatMultAndMatTransMult_v1_aX_b1_xsX_ysX_oX_z1_wsX_zsX MANGLE_MOD_(MBCSR_MatMultAndMatTransMult_v1_aX_b1_xsX_ysX_oX_z1_wsX_zsX_4x2) |
| | Mangled name for MBCSR_MatMultAndMatTransMult_v1_aX_b1_xsX_ysX_oX_z1_wsX_zsX.
|
|
#define | SubmatReprMultAndSubmatReprTransMult MANGLE_MOD_(SubmatReprMultAndSubmatReprTransMult_4x2) |
| | Mangled name for primary exportable symbol.
|
Functions |
|
void | MBCSR_MatMultAndMatMult_v1_aX_b1_xs1_ysX_oX_z1_ws1_zsX (oski_index_t M, oski_index_t d0, const oski_index_t *restrict ptr, const oski_index_t *restrict ind, const oski_value_t *restrict val, const oski_value_t *restrict diag, oski_value_t alpha, const oski_value_t *restrict x, oski_value_t *restrict y, oski_index_t incy, oski_value_t omega, const oski_value_t *restrict w, oski_value_t *restrict z, oski_index_t incz) |
| | The 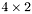 MBCSR implementation of MBCSR implementation of  , where x, y, w, and z vectors have unit-stride, general-stride, unit-stride, and general-stride, respectively. , where x, y, w, and z vectors have unit-stride, general-stride, unit-stride, and general-stride, respectively.
|
|
void | MBCSR_MatMultAndMatMult_v1_aX_b1_xsX_ysX_oX_z1_wsX_zsX (oski_index_t M, oski_index_t d0, const oski_index_t *restrict ptr, const oski_index_t *restrict ind, const oski_value_t *restrict val, const oski_value_t *restrict diag, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t incx, oski_value_t *restrict y, oski_index_t incy, oski_value_t omega, const oski_value_t *restrict w, oski_index_t incw, oski_value_t *restrict z, oski_index_t incz) |
| | The MBCSR implementation of , where x, y, w, and z vectors have general-stride, general-stride, general-stride, and general-stride, respectively.
|
|
static int | MatMultAndMatMult (const oski_submatMBCSR_t *A, oski_value_t alpha, const oski_vecview_t x, oski_vecview_t y, oski_value_t omega, const oski_vecview_t w, oski_vecview_t z) |
| | Exported module wrapper for the implementation of .
|
|
static int | MatMultAndMatConjMult (const oski_submatMBCSR_t *A, oski_value_t alpha, const oski_vecview_t x, oski_vecview_t y, oski_value_t omega, const oski_vecview_t w, oski_vecview_t z) |
| | Exported module wrapper for the implementation of  . .
|
|
void | MBCSR_MatMultAndMatTransMult_v1_aX_b1_xs1_ysX_oX_z1_wsX_zs1 (oski_index_t M, oski_index_t d0, const oski_index_t *restrict ptr, const oski_index_t *restrict ind, const oski_value_t *restrict val, const oski_value_t *restrict diag, oski_value_t alpha, const oski_value_t *restrict x, oski_value_t *restrict y, oski_index_t incy, oski_value_t omega, const oski_value_t *restrict w, oski_index_t incw, oski_value_t *restrict z) |
| | The MBCSR implementation of  , where x, y, w, and z vectors have unit-stride, general-stride, general-stride, and unit-stride, respectively. , where x, y, w, and z vectors have unit-stride, general-stride, general-stride, and unit-stride, respectively.
|
|
void | MBCSR_MatMultAndMatTransMult_v1_aX_b1_xsX_ysX_oX_z1_wsX_zsX (oski_index_t M, oski_index_t d0, const oski_index_t *restrict ptr, const oski_index_t *restrict ind, const oski_value_t *restrict val, const oski_value_t *restrict diag, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t incx, oski_value_t *restrict y, oski_index_t incy, oski_value_t omega, const oski_value_t *restrict w, oski_index_t incw, oski_value_t *restrict z, oski_index_t incz) |
| | The MBCSR implementation of , where x, y, w, and z vectors have general-stride, general-stride, general-stride, and general-stride, respectively.
|
|
static int | MatMultAndMatTransMult (const oski_submatMBCSR_t *A, oski_value_t alpha, const oski_vecview_t x, oski_vecview_t y, oski_value_t omega, const oski_vecview_t w, oski_vecview_t z) |
| | Exported module wrapper for the implementation of .
|
|
static int | MatMultAndMatHermMult (const oski_submatMBCSR_t *A, oski_value_t alpha, const oski_vecview_t x, oski_vecview_t y, oski_value_t omega, const oski_vecview_t w, oski_vecview_t z) |
| | Exported module wrapper for the implementation of  . .
|
|
int | SubmatReprMultAndSubmatReprTransMult (const oski_submatMBCSR_t *A, oski_value_t alpha, const oski_vecview_t x, oski_vecview_t y, oski_matop_t opA, oski_value_t omega, const oski_vecview_t w, oski_vecview_t z) |
| | Entry point to the 4x2 kernel that implements simultaneous multiplication by sparse 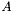 and and 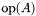 . .
|
