Defines
Functions
 .
.  .
.  , where
, where 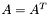 and
and  .
.
#include <assert.h>
#include <oski/config.h>
#include <oski/common.h>
#include <oski/blas.h>
#include <oski/matmult.h>
#include <oski/CSR/format.h>
#include <oski/CSR/module.h>
#include "MatMult/CSR_MatMult.h"
#include "SymmMatMult/CSR_SymmMatMult.h"
#include "SymmMatMult/CSR_SymmMatHermMult.h"
#include "SymmMatMult/CSR_HermMatMult.h"
#include "SymmMatMult/CSR_HermMatTransMult.h"
Defines | |
| #define | CSR_MatConjMult_v1 CSR_MatMult_v1 |
| Base-adjusted, matrix times single-vector multiply. | |
| #define | MatReprMult_Conj MatReprMult_Normal |
Functions | |
| static void | CSR_MatMult_v1 (oski_index_t m, oski_index_t n, const oski_index_t *ptr, const oski_index_t *ind, const oski_value_t *val, oski_value_t alpha, const oski_value_t *x, oski_index_t incx, oski_value_t *y, oski_index_t incy) |
| Base-adjusted, matrix times single-vector multiply. | |
| static int | MatReprMult_Normal (const oski_matCSR_t *A, const oski_matcommon_t *props, oski_value_t alpha, const oski_vecview_t x_view, oski_vecview_t y_view) |
| CSR-specific matrix-vector multiply operation, . | |
| static void | CSR_MatTransMult_v1 (oski_index_t m, oski_index_t n, const oski_index_t *ptr, const oski_index_t *ind, const oski_value_t *val, oski_value_t alpha, const oski_value_t *x, oski_index_t incx, oski_value_t *y, oski_index_t incy) |
| Base-adjusted, matrix-transpose times single-vector multiply. | |
| static int | MatReprMult_Trans (const oski_matCSR_t *A, const oski_matcommon_t *props, oski_value_t alpha, const oski_vecview_t x_view, oski_vecview_t y_view) |
| CSR-specific matrix-vector multiply operation, . | |
| static void | SymmMatMult_v1 (oski_index_t m, oski_index_t n, const oski_index_t *ptr, const oski_index_t *ind, const oski_value_t *val, oski_index_t base, oski_value_t alpha, const oski_value_t *x, oski_index_t incx, oski_value_t *y, oski_index_t incy) |
| Single-vector implementation of symmetric CSR SpMV. | |
| static int | SymmMatMult (const oski_matCSR_t *A, const oski_matcommon_t *props, oski_matop_t opA, oski_value_t alpha, const oski_vecview_t x_view, oski_vecview_t y_view) |
| Symmetric matrix-vector multiply, , where and . | |
| int | oski_MatReprMult (const void *pA, const oski_matcommon_t *props, oski_matop_t opA, oski_value_t alpha, const oski_vecview_t x_view, oski_value_t beta, oski_vecview_t y_view) |
| Matrix type-specific implementation of sparse matrix-vector multiply. | |
|
||||||||||||||||||||||||
|
CSR-specific matrix-vector multiply operation, At present, this implementation does not handle the multiple vector case specially.
|
|
||||||||||||||||||||||||
|
CSR-specific matrix-vector multiply operation, At present, this implementation does not handle the multiple vector case specially.
|
|
||||||||||||||||||||||||||||
|
Symmetric matrix-vector multiply,
At present, the multiple-vector implementation just repeatedly calls the single-vector implementation. |
 1.4.6
1.4.6
 .
.