Automatically generated by ./gen_csr_nonsymm.sh and ../../../build/gen/driver/oski_spgen on Tue Nov 23 15:06:01 PST 2004.
|
Defines |
|
#define | INC_CSR_MatMult |
| | src/CSR/MatMult/CSR_MatMult.h included.
|
|
#define | CSR_MatMult_v1_aN1_b1_xs1_ysX MANGLE_(CSR_MatMult_v1_aN1_b1_xs1_ysX) |
| | Mangled name for CSR_MatMult_v1_aN1_b1_xs1_ysX().
|
|
#define | CSR_MatMult_v1_aN1_b1_xsX_ysX MANGLE_(CSR_MatMult_v1_aN1_b1_xsX_ysX) |
| | Mangled name for CSR_MatMult_v1_aN1_b1_xsX_ysX().
|
|
#define | CSR_MatMult_v1_a1_b1_xs1_ysX MANGLE_(CSR_MatMult_v1_a1_b1_xs1_ysX) |
| | Mangled name for CSR_MatMult_v1_a1_b1_xs1_ysX().
|
|
#define | CSR_MatMult_v1_a1_b1_xsX_ysX MANGLE_(CSR_MatMult_v1_a1_b1_xsX_ysX) |
| | Mangled name for CSR_MatMult_v1_a1_b1_xsX_ysX().
|
|
#define | CSR_MatMult_v1_aX_b1_xs1_ysX MANGLE_(CSR_MatMult_v1_aX_b1_xs1_ysX) |
| | Mangled name for CSR_MatMult_v1_aX_b1_xs1_ysX().
|
|
#define | CSR_MatMult_v1_aX_b1_xsX_ysX MANGLE_(CSR_MatMult_v1_aX_b1_xsX_ysX) |
| | Mangled name for CSR_MatMult_v1_aX_b1_xsX_ysX().
|
|
#define | CSR_MatTransMult_v1_aN1_b1_xsX_ys1 MANGLE_(CSR_MatTransMult_v1_aN1_b1_xsX_ys1) |
| | Mangled name for CSR_MatTransMult_v1_aN1_b1_xsX_ys1().
|
|
#define | CSR_MatTransMult_v1_aN1_b1_xsX_ysX MANGLE_(CSR_MatTransMult_v1_aN1_b1_xsX_ysX) |
| | Mangled name for CSR_MatTransMult_v1_aN1_b1_xsX_ysX().
|
|
#define | CSR_MatTransMult_v1_a1_b1_xsX_ys1 MANGLE_(CSR_MatTransMult_v1_a1_b1_xsX_ys1) |
| | Mangled name for CSR_MatTransMult_v1_a1_b1_xsX_ys1().
|
|
#define | CSR_MatTransMult_v1_a1_b1_xsX_ysX MANGLE_(CSR_MatTransMult_v1_a1_b1_xsX_ysX) |
| | Mangled name for CSR_MatTransMult_v1_a1_b1_xsX_ysX().
|
|
#define | CSR_MatTransMult_v1_aX_b1_xsX_ys1 MANGLE_(CSR_MatTransMult_v1_aX_b1_xsX_ys1) |
| | Mangled name for CSR_MatTransMult_v1_aX_b1_xsX_ys1().
|
|
#define | CSR_MatTransMult_v1_aX_b1_xsX_ysX MANGLE_(CSR_MatTransMult_v1_aX_b1_xsX_ysX) |
| | Mangled name for CSR_MatTransMult_v1_aX_b1_xsX_ysX().
|
Functions |
|
void | CSR_MatMult_v1_aN1_b1_xs1_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation 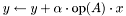 , where , where 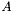 is real-valued, is real-valued, 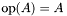 , , 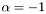 , , 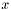 is unit-stride accessible, and is unit-stride accessible, and 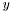 is general-stride accessible. is general-stride accessible.
|
|
void | CSR_MatMult_v1_aN1_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is real-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatMult_v1_a1_b1_xs1_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is real-valued, , 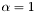 , is unit-stride accessible, and is general-stride accessible. , is unit-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatMult_v1_a1_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is real-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatMult_v1_aX_b1_xs1_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, oski_value_t alpha, const oski_value_t *restrict x, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is real-valued, , 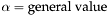 , is unit-stride accessible, and is general-stride accessible. , is unit-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatMult_v1_aX_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is real-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatTransMult_v1_aN1_b1_xsX_ys1 (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y) |
| | Computes the SpMV operation , where is real-valued, 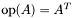 , , is general-stride accessible, and is unit-stride accessible. , , is general-stride accessible, and is unit-stride accessible.
|
|
void | CSR_MatTransMult_v1_aN1_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is real-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatTransMult_v1_a1_b1_xsX_ys1 (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y) |
| | Computes the SpMV operation , where is real-valued, , , is general-stride accessible, and is unit-stride accessible.
|
|
void | CSR_MatTransMult_v1_a1_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is real-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatTransMult_v1_aX_b1_xsX_ys1 (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y) |
| | Computes the SpMV operation , where is real-valued, , , is general-stride accessible, and is unit-stride accessible.
|
|
void | CSR_MatTransMult_v1_aX_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is real-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatHermMult_v1_aN1_b1_xsX_ys1 (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y) |
| | Computes the SpMV operation , where is complex-valued, 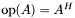 , , is general-stride accessible, and is unit-stride accessible. , , is general-stride accessible, and is unit-stride accessible.
|
|
void | CSR_MatHermMult_v1_aN1_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is complex-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatHermMult_v1_a1_b1_xsX_ys1 (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y) |
| | Computes the SpMV operation , where is complex-valued, , , is general-stride accessible, and is unit-stride accessible.
|
|
void | CSR_MatHermMult_v1_a1_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is complex-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatHermMult_v1_aX_b1_xsX_ys1 (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y) |
| | Computes the SpMV operation , where is complex-valued, , , is general-stride accessible, and is unit-stride accessible.
|
|
void | CSR_MatHermMult_v1_aX_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is complex-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatConjMult_v1_aN1_b1_xs1_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is complex-valued,  , , is unit-stride accessible, and is general-stride accessible. , , is unit-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatConjMult_v1_aN1_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is complex-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatConjMult_v1_a1_b1_xs1_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is complex-valued, , , is unit-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatConjMult_v1_a1_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is complex-valued, , , is general-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatConjMult_v1_aX_b1_xs1_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, oski_value_t alpha, const oski_value_t *restrict x, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is complex-valued, , , is unit-stride accessible, and is general-stride accessible.
|
|
void | CSR_MatConjMult_v1_aX_b1_xsX_ysX (oski_index_t A_M, oski_index_t A_N, const oski_index_t *restrict A_ptr, const oski_index_t *restrict A_ind, const oski_value_t *restrict A_val, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t xstride, oski_value_t *restrict y, oski_index_t ystride) |
| | Computes the SpMV operation , where is complex-valued, , , is general-stride accessible, and is general-stride accessible.
|
