| GCSR/MatMult/1x1.c | The 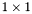 GCSR implementation of simultaneous multiplication by GCSR implementation of simultaneous multiplication by 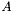 and and 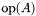 |
| MBCSR/MatMult/1x1.c | MBCSR 1x1 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/1x1.c | The MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/1x1.c | The MBCSR implementation of 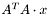 and and 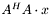 |
| MBCSR/MatTrisolve/1x1.c | The MBCSR implementation of sparse triangular solve |
| GCSR/MatMult/1x2.c | The 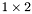 GCSR implementation of simultaneous multiplication by and GCSR implementation of simultaneous multiplication by and |
| MBCSR/MatMult/1x2.c | MBCSR 1x2 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/1x2.c | The MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/1x2.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/1x2.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/1x3.c | MBCSR 1x3 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/1x3.c | The 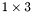 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/1x3.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/1x3.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/1x4.c | MBCSR 1x4 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/1x4.c | The 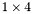 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/1x4.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/1x4.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/1x5.c | MBCSR 1x5 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/1x5.c | The 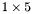 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/1x5.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/1x5.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/1x6.c | MBCSR 1x6 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/1x6.c | The 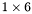 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/1x6.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/1x6.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/1x7.c | MBCSR 1x7 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/1x7.c | The 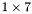 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/1x7.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/1x7.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/1x8.c | MBCSR 1x8 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/1x8.c | The 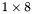 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/1x8.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/1x8.c | The MBCSR implementation of sparse triangular solve |
| GCSR/MatMult/2x1.c | The 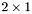 GCSR implementation of simultaneous multiplication by and GCSR implementation of simultaneous multiplication by and |
| MBCSR/MatMult/2x1.c | MBCSR 2x1 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/2x1.c | The MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/2x1.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/2x1.c | The MBCSR implementation of sparse triangular solve |
| GCSR/MatMult/2x2.c | The 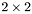 GCSR implementation of simultaneous multiplication by and GCSR implementation of simultaneous multiplication by and |
| MBCSR/MatMult/2x2.c | MBCSR 2x2 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/2x2.c | The MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/2x2.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/2x2.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/2x3.c | MBCSR 2x3 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/2x3.c | The 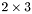 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/2x3.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/2x3.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/2x4.c | MBCSR 2x4 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/2x4.c | The 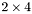 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/2x4.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/2x4.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/2x5.c | MBCSR 2x5 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/2x5.c | The 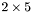 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/2x5.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/2x5.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/2x6.c | MBCSR 2x6 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/2x6.c | The 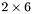 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/2x6.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/2x6.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/2x7.c | MBCSR 2x7 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/2x7.c | The 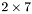 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/2x7.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/2x7.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/2x8.c | MBCSR 2x8 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/2x8.c | The 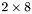 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/2x8.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/2x8.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/3x1.c | MBCSR 3x1 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/3x1.c | The 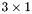 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/3x1.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/3x1.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/3x2.c | MBCSR 3x2 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/3x2.c | The 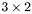 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/3x2.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/3x2.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/3x3.c | MBCSR 3x3 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/3x3.c | The 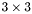 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/3x3.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/3x3.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/3x4.c | MBCSR 3x4 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/3x4.c | The 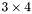 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/3x4.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/3x4.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/3x5.c | MBCSR 3x5 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/3x5.c | The 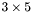 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/3x5.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/3x5.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/3x6.c | MBCSR 3x6 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/3x6.c | The 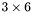 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/3x6.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/3x6.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/3x7.c | MBCSR 3x7 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/3x7.c | The 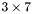 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/3x7.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/3x7.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/3x8.c | MBCSR 3x8 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/3x8.c | The 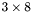 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/3x8.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/3x8.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/4x1.c | MBCSR 4x1 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/4x1.c | The 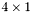 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/4x1.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/4x1.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/4x2.c | MBCSR 4x2 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/4x2.c | The 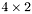 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/4x2.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/4x2.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/4x3.c | MBCSR 4x3 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/4x3.c | The 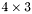 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/4x3.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/4x3.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/4x4.c | MBCSR 4x4 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/4x4.c | The 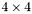 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/4x4.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/4x4.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/4x5.c | MBCSR 4x5 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/4x5.c | The 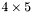 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/4x5.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/4x5.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/4x6.c | MBCSR 4x6 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/4x6.c | The 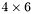 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/4x6.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/4x6.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/4x7.c | MBCSR 4x7 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/4x7.c | The 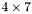 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/4x7.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/4x7.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/4x8.c | MBCSR 4x8 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/4x8.c | The 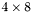 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/4x8.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/4x8.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/5x1.c | MBCSR 5x1 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/5x1.c | The 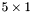 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/5x1.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/5x1.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/5x2.c | MBCSR 5x2 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/5x2.c | The 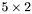 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/5x2.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/5x2.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/5x3.c | MBCSR 5x3 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/5x3.c | The 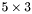 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/5x3.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/5x3.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/5x4.c | MBCSR 5x4 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/5x4.c | The 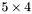 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/5x4.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/5x4.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/5x5.c | MBCSR 5x5 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/5x5.c | The 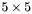 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/5x5.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/5x5.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/5x6.c | MBCSR 5x6 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/5x6.c | The 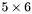 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/5x6.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/5x6.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/5x7.c | MBCSR 5x7 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/5x7.c | The 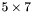 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/5x7.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/5x7.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/5x8.c | MBCSR 5x8 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/5x8.c | The 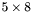 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/5x8.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/5x8.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/6x1.c | MBCSR 6x1 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/6x1.c | The 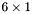 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/6x1.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/6x1.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/6x2.c | MBCSR 6x2 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/6x2.c | The 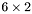 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/6x2.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/6x2.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/6x3.c | MBCSR 6x3 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/6x3.c | The 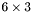 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/6x3.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/6x3.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/6x4.c | MBCSR 6x4 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/6x4.c | The 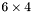 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/6x4.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/6x4.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/6x5.c | MBCSR 6x5 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/6x5.c | The 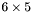 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/6x5.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/6x5.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/6x6.c | MBCSR 6x6 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/6x6.c | The 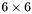 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/6x6.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/6x6.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/6x7.c | MBCSR 6x7 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/6x7.c | The 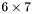 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/6x7.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/6x7.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/6x8.c | MBCSR 6x8 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/6x8.c | The 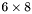 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/6x8.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/6x8.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/7x1.c | MBCSR 7x1 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/7x1.c | The 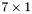 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/7x1.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/7x1.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/7x2.c | MBCSR 7x2 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/7x2.c | The 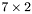 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/7x2.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/7x2.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/7x3.c | MBCSR 7x3 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/7x3.c | The 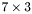 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/7x3.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/7x3.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/7x4.c | MBCSR 7x4 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/7x4.c | The 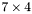 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/7x4.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/7x4.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/7x5.c | MBCSR 7x5 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/7x5.c | The 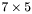 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/7x5.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/7x5.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/7x6.c | MBCSR 7x6 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/7x6.c | The 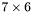 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/7x6.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/7x6.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/7x7.c | MBCSR 7x7 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/7x7.c | The 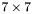 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/7x7.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/7x7.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/7x8.c | MBCSR 7x8 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/7x8.c | The 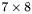 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/7x8.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/7x8.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/8x1.c | MBCSR 8x1 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/8x1.c | The 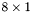 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/8x1.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/8x1.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/8x2.c | MBCSR 8x2 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/8x2.c | The 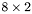 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/8x2.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/8x2.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/8x3.c | MBCSR 8x3 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/8x3.c | The 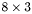 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/8x3.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/8x3.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/8x4.c | MBCSR 8x4 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/8x4.c | The 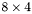 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/8x4.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/8x4.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/8x5.c | MBCSR 8x5 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/8x5.c | The 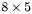 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/8x5.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/8x5.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/8x6.c | MBCSR 8x6 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/8x6.c | The 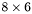 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/8x6.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/8x6.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/8x7.c | MBCSR 8x7 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/8x7.c | The 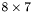 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/8x7.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/8x7.c | The MBCSR implementation of sparse triangular solve |
| MBCSR/MatMult/8x8.c | MBCSR 8x8 SpMV implementation, for all transpose options |
| MBCSR/MatMultAndMatTransMult/8x8.c | The 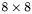 MBCSR implementation of simultaneous multiplication by and MBCSR implementation of simultaneous multiplication by and |
| MBCSR/MatTransMatMult/8x8.c | The MBCSR implementation of and |
| MBCSR/MatTrisolve/8x8.c | The MBCSR implementation of sparse triangular solve |
| a_and_at.c | Implementation of simultaneously multiplication by sparse and 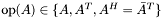 |
| MATTYPE_TEMPLATE/a_and_at.c | MATTYPE_TEMPLATE implementation of the simultaneous multiplication by sparse and 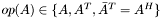 |
| MBCSR/a_and_at.c | MBCSR implementation of the simultaneous multiplication by sparse and |
| a_and_at.h [code] | Sparse simultaneous multiplication by and 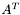 |
| abort_prog.h [code] | Macro to abort a program on error |
| alloc.c | Test OSKI memory allocation routines |
| array_util.c | Some utility functions for the test suite |
| array_util.h [code] | Some array manipulation utility functions for the test suite |
| src/ata.c | Sparse implementation |
| src/BCSR/ata.c | BCSR implementation of the A^T*A*x kernel |
| src/MATTYPE_TEMPLATE/ata.c | MATTYPE_TEMPLATE implementation of the sparse kernel |
| src/MBCSR/ata.c | MBCSR implementation of the sparse kernel |
| tests/ata.c | Test sparse matrix-vector multiply |
| ata.h [code] | Sparse implementation |
| autotune.c | Generic SpMV benchmarking utility |
| bcsr.c | Test basic kernel operations for a matrix in BCSR format |
| bench.c | Generic workload benchmarking utility |
| blas.c | OSKI wrappers around the dense BLAS routines |
| blas.h [code] | BeBOP wrappers around the dense BLAS routines |
| blas1.c | Test BLAS 1 wrappers |
| blas_names.h [code] | Header containing mangled F77 BLAS routine names |
| check.c | Check CSR properties |
| common.h [code] | A maximal set of system-independent prototypes and definitions widely useful to all of the BeBOP library's sub-modules |
| config.h [code] | Contains macros and definitions that depend on the specific system on which the library is being compiled |
| src/BCSR/convert.c | Conversion between CSR and SPARSITY-style BCSR (i.e., register blocking) format |
| src/BDIAG1/convert.c | Conversion between CSR and BDIAG1 format |
| src/CB/convert.c | CSR-to-CB format conversion routines |
| src/MATTYPE_TEMPLATE/convert.c | Conversion between CSR and MATTYPE_TEMPLATE format |
| src/MBCSR/convert.c | Conversion between CSR and MBCSR format |
| src/VBR/convert.c | Conversion between CSR and VBR format |
| tests/convert.c | Test matrix conversion |
| copy.c | Test matrix and vector handle copying |
| create.c | Test matrix handle creation |
| CSR_HermMatMult.h [code] | Prototypes for subroutines that compute variations on 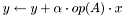 , where is Hermitian (i.e., , where is Hermitian (i.e., 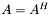 ) and ) and 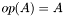 |
| CSR_HermMatMult_v1_a1_b1_xs1_ys1.c | 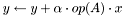 , where is Hermitian (i.e., ), , , where is Hermitian (i.e., ), ,  , x is unit-stride accessible, and y is unit-stride accessible , x is unit-stride accessible, and y is unit-stride accessible |
| CSR_HermMatMult_v1_a1_b1_xs1_ysX.c | , where is Hermitian (i.e., ), , , x is unit-stride accessible, and y is general-stride accessible |
| CSR_HermMatMult_v1_a1_b1_xsX_ys1.c | , where is Hermitian (i.e., ), , , x is general-stride accessible, and y is unit-stride accessible |
| CSR_HermMatMult_v1_a1_b1_xsX_ysX.c | , where is Hermitian (i.e., ), , , x is general-stride accessible, and y is general-stride accessible |
| CSR_HermMatMult_v1_aN1_b1_xs1_ys1.c | , where is Hermitian (i.e., ), , 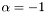 , x is unit-stride accessible, and y is unit-stride accessible , x is unit-stride accessible, and y is unit-stride accessible |
| CSR_HermMatMult_v1_aN1_b1_xs1_ysX.c | , where is Hermitian (i.e., ), , , x is unit-stride accessible, and y is general-stride accessible |
| CSR_HermMatMult_v1_aN1_b1_xsX_ys1.c | , where is Hermitian (i.e., ), , , x is general-stride accessible, and y is unit-stride accessible |
| CSR_HermMatMult_v1_aN1_b1_xsX_ysX.c | , where is Hermitian (i.e., ), , , x is general-stride accessible, and y is general-stride accessible |
| CSR_HermMatMult_v1_aX_b1_xs1_ys1.c | , where is Hermitian (i.e., ), , 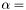 (a general value), x is unit-stride accessible, and y is unit-stride accessible (a general value), x is unit-stride accessible, and y is unit-stride accessible |
| CSR_HermMatMult_v1_aX_b1_xs1_ysX.c | , where is Hermitian (i.e., ), , (a general value), x is unit-stride accessible, and y is general-stride accessible |
| CSR_HermMatMult_v1_aX_b1_xsX_ys1.c | , where is Hermitian (i.e., ), , (a general value), x is general-stride accessible, and y is unit-stride accessible |
| CSR_HermMatMult_v1_aX_b1_xsX_ysX.c | , where is Hermitian (i.e., ), , (a general value), x is general-stride accessible, and y is general-stride accessible |
| CSR_HermMatTransMult.h [code] | Prototypes for subroutines that compute variations on , where is Hermitian (i.e., ) and 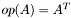 |
| CSR_HermMatTransMult_v1_a1_b1_xs1_ys1.c | , where is Hermitian (i.e., ), , , x is unit-stride accessible, and y is unit-stride accessible |
| CSR_HermMatTransMult_v1_a1_b1_xs1_ysX.c | , where is Hermitian (i.e., ), , , x is unit-stride accessible, and y is general-stride accessible |
| CSR_HermMatTransMult_v1_a1_b1_xsX_ys1.c | , where is Hermitian (i.e., ), , , x is general-stride accessible, and y is unit-stride accessible |
| CSR_HermMatTransMult_v1_a1_b1_xsX_ysX.c | , where is Hermitian (i.e., ), , , x is general-stride accessible, and y is general-stride accessible |
| CSR_HermMatTransMult_v1_aN1_b1_xs1_ys1.c | , where is Hermitian (i.e., ), , , x is unit-stride accessible, and y is unit-stride accessible |
| CSR_HermMatTransMult_v1_aN1_b1_xs1_ysX.c | , where is Hermitian (i.e., ), , , x is unit-stride accessible, and y is general-stride accessible |
| CSR_HermMatTransMult_v1_aN1_b1_xsX_ys1.c | , where is Hermitian (i.e., ), , , x is general-stride accessible, and y is unit-stride accessible |
| CSR_HermMatTransMult_v1_aN1_b1_xsX_ysX.c | , where is Hermitian (i.e., ), , , x is general-stride accessible, and y is general-stride accessible |
| CSR_HermMatTransMult_v1_aX_b1_xs1_ys1.c | , where is Hermitian (i.e., ), , (a general value), x is unit-stride accessible, and y is unit-stride accessible |
| CSR_HermMatTransMult_v1_aX_b1_xs1_ysX.c | , where is Hermitian (i.e., ), , (a general value), x is unit-stride accessible, and y is general-stride accessible |
| CSR_HermMatTransMult_v1_aX_b1_xsX_ys1.c | , where is Hermitian (i.e., ), , (a general value), x is general-stride accessible, and y is unit-stride accessible |
| CSR_HermMatTransMult_v1_aX_b1_xsX_ysX.c | , where is Hermitian (i.e., ), , (a general value), x is general-stride accessible, and y is general-stride accessible |
| CSR_MatMult.h [code] | CSR sparse matrix-vector multiply implementation in the non-symmetric/non-Hermitian case |
| CSR_SymmMatHermMult.h [code] | Prototypes for subroutines that compute variations on , where is symmetric (i.e., 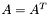 ) and ) and 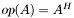 |
| CSR_SymmMatHermMult_v1_a1_b1_xs1_ys1.c | , where is symmetric (i.e., ), , , x is unit-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatHermMult_v1_a1_b1_xs1_ysX.c | , where is symmetric (i.e., ), , , x is unit-stride accessible, and y is general-stride accessible |
| CSR_SymmMatHermMult_v1_a1_b1_xsX_ys1.c | , where is symmetric (i.e., ), , , x is general-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatHermMult_v1_a1_b1_xsX_ysX.c | , where is symmetric (i.e., ), , , x is general-stride accessible, and y is general-stride accessible |
| CSR_SymmMatHermMult_v1_aN1_b1_xs1_ys1.c | , where is symmetric (i.e., ), , , x is unit-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatHermMult_v1_aN1_b1_xs1_ysX.c | , where is symmetric (i.e., ), , , x is unit-stride accessible, and y is general-stride accessible |
| CSR_SymmMatHermMult_v1_aN1_b1_xsX_ys1.c | , where is symmetric (i.e., ), , , x is general-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatHermMult_v1_aN1_b1_xsX_ysX.c | , where is symmetric (i.e., ), , , x is general-stride accessible, and y is general-stride accessible |
| CSR_SymmMatHermMult_v1_aX_b1_xs1_ys1.c | , where is symmetric (i.e., ), , (a general value), x is unit-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatHermMult_v1_aX_b1_xs1_ysX.c | , where is symmetric (i.e., ), , (a general value), x is unit-stride accessible, and y is general-stride accessible |
| CSR_SymmMatHermMult_v1_aX_b1_xsX_ys1.c | , where is symmetric (i.e., ), , (a general value), x is general-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatHermMult_v1_aX_b1_xsX_ysX.c | , where is symmetric (i.e., ), , (a general value), x is general-stride accessible, and y is general-stride accessible |
| CSR_SymmMatMult.h [code] | Prototypes for subroutines that compute variations on , where is symmetric (i.e., ) and |
| CSR_SymmMatMult_v1_a1_b1_xs1_ys1.c | , where is symmetric (i.e., ), , , x is unit-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatMult_v1_a1_b1_xs1_ysX.c | , where is symmetric (i.e., ), , , x is unit-stride accessible, and y is general-stride accessible |
| CSR_SymmMatMult_v1_a1_b1_xsX_ys1.c | , where is symmetric (i.e., ), , , x is general-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatMult_v1_a1_b1_xsX_ysX.c | , where is symmetric (i.e., ), , , x is general-stride accessible, and y is general-stride accessible |
| CSR_SymmMatMult_v1_aN1_b1_xs1_ys1.c | , where is symmetric (i.e., ), , , x is unit-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatMult_v1_aN1_b1_xs1_ysX.c | , where is symmetric (i.e., ), , , x is unit-stride accessible, and y is general-stride accessible |
| CSR_SymmMatMult_v1_aN1_b1_xsX_ys1.c | , where is symmetric (i.e., ), , , x is general-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatMult_v1_aN1_b1_xsX_ysX.c | , where is symmetric (i.e., ), , , x is general-stride accessible, and y is general-stride accessible |
| CSR_SymmMatMult_v1_aX_b1_xs1_ys1.c | , where is symmetric (i.e., ), , (a general value), x is unit-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatMult_v1_aX_b1_xs1_ysX.c | , where is symmetric (i.e., ), , (a general value), x is unit-stride accessible, and y is general-stride accessible |
| CSR_SymmMatMult_v1_aX_b1_xsX_ys1.c | , where is symmetric (i.e., ), , (a general value), x is general-stride accessible, and y is unit-stride accessible |
| CSR_SymmMatMult_v1_aX_b1_xsX_ysX.c | , where is symmetric (i.e., ), , (a general value), x is general-stride accessible, and y is general-stride accessible |
| cycle.h [code] | Cycle counter readers, taken from FFTW 3.0.1 |
| tests/debug.c | Test the rudimentary debugging/logging facility |
| debug.h [code] | Debugging support module |
| err.c | Test OSKI error handling facilities |
| error.c | Error-handling module |
| error.h [code] | Error-handling module |
| estfill.c | BCSR fill ratio estimator |
| estfill.h [code] | BCSR fill ratio estimator |
| BCSR/format.h [code] | Block compressed sparse row data structure |
| BDIAG1/format.h [code] | Single block diagonal data structure |
| CB/format.h [code] | Cache blocking data structure |
| CSC/format.h [code] | Compressed sparse column data structure |
| CSR/format.h [code] | Compressed sparse row data structure |
| DENSE/format.h [code] | Generalized compressed sparse row data structure |
| GCSR/format.h [code] | Generalized compressed sparse row data structure |
| MATTYPE_TEMPLATE/format.h [code] | Custom matrix data structure |
| MBCSR/format.h [code] | Modified block compressed sparse row data structure |
| TRIPART/format.h [code] | \ Block compressed sparse row data structure |
| VBR/format.h [code] | Generalized compressed sparse row data structure |
| gemv.c | OSKI wrapper around the dense BLAS routine, xGEMV |
| getcpu.c | Get the CPU architecture using a run-time probe |
| src/BCSR/getset.c | BCSR get/set value routines |
| src/BDIAG1/getset.c | BDIAG1 get/set value routines |
| src/CB/getset.c | CB get/set value routines |
| src/CSC/getset.c | CSC get/set value routines |
| src/CSR/getset.c | CSR get/set value routines |
| src/DENSE/getset.c | DENSE get/set value routines |
| src/GCSR/getset.c | GCSR get/set value routines |
| src/getset.c | Get/set value routines |
| src/MATTYPE_TEMPLATE/getset.c | MATTYPE_TEMPLATE get/set value routines |
| src/MBCSR/getset.c | MBCSR get/set value routines |
| src/VBR/getset.c | VBR get/set value routines |
| tests/getset.c | Get/set matrix values |
| getset.h [code] | Get/set value routines |
| hba_and_at.c | Comprehensive test of the kernel for applying sparse and simultaneously |
| hbata.c | Comprehensive test of sparse 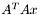 kernel routine, oski_MatTransMatMult(), for an arbitrary data structure transformation (specified by a OSKI-Lua program), where the matrix is read from a Harwell-Boeing file kernel routine, oski_MatTransMatMult(), for an arbitrary data structure transformation (specified by a OSKI-Lua program), where the matrix is read from a Harwell-Boeing file |
| hbmatmult.c | Comprehensive test of matrix-vector multiply for an arbitrary data structure transformation (specified by a OSKI-Lua program), where the matrix is read from a Harwell-Boeing file |
| tests/heur.c | Test sparse matrix-vector multiply tuning |
| heur.h [code] | Heuristic management module |
| heur2.c | Additional testing of the heuristic |
| heur_internal.h [code] | Heuristic management module |
| heur_typedep.c | Matrix type-dependent part of the heuristic module |
| heur_typedep.h [code] | Matrix type-dependent part of the heuristic module |
| heurexport.h [code] | Matrix type-dependent part of the heuristic management module |
| hint.c | Implementation of hint tracking for the tuning module |
| hint.h [code] | Set-hint routines |
| info.c | Test scalar/kernel info lookup routines |
| src/init.c | Initialize the OSKI library |
| tests/init.c | Test the matrix type management module |
| init.h [code] | BeBOP library initialization |
| inmatprop.c | Input matrix properties collection and inspection |
| inmatprop.h [code] | Input matrix properties collection and inspection |
| kerinfo.h [code] | Define the kernels available to the library |
| keropts.c | Process kernel-specific command-line options |
| keropts.h [code] | Process kernel-specific command-line options |
| lower_conj.c | Conjugate sparse triangular solve implementation when the matrix is lower triangular and stored in CSR format |
| lower_conjtrans.c | Conjugate-transposed sparse triangular solve implementation when the matrix is lower triangular and stored in CSR format |
| lower_normal.c | Non-transposed sparse triangular solve implementation when the matrix is lower triangular and stored in CSR format |
| lower_trans.c | Transposed sparse triangular solve implementation when the matrix is lower triangular and stored in CSR format |
| ltdlstub.c | Stub file to define lt_preloaded_symbols in the case when we do not link using libtool |
| lua.c | OSKI-Lua stack support |
| lua.h [code] | Basic OSKI-Lua support routines |
| malloc.h [code] | Customized memory allocation macros that provide diagnostic information when out-of-memory errors occur |
| mangle.h [code] | Some macros to mangle index/value type-specific names |
| matcommon.c | Support routines for the data structure containing common matrix properties |
| matcommon.h [code] | Define properties common to all matrix types |
| matcreate.c | Matrix creation routines |
| matcreate.h [code] | Matrix creation routines |
| matmodexport.h [code] | Declares prototypes for the 'standard' set of dynamically exportable methods stored in matrix type modules |
| src/BCSR/matmult.c | BCSR implementation of SpMV |
| src/BDIAG1/matmult.c | BDIAG1 implementation of SpMV |
| src/CB/matmult.c | Sparse matrix-vector multiply implementation for a compressed sparse row (CB) matrix |
| src/CSC/matmult.c | CSC SpMV implementation |
| src/CSR/matmult.c | Sparse matrix-vector multiply implementation for a compressed sparse row (CSR) matrix |
| src/DENSE/matmult.c | Calls xGEMV / xGEMM |
| src/GCSR/matmult.c | Sparse matrix-vector multiply implementation for a compressed sparse row (GCSR) matrix |
| src/matmult.c | Sparse matrix-vector multiply implementation |
| src/MATTYPE_TEMPLATE/matmult.c | MATTYPE_TEMPLATE implementation of SpMV |
| src/MBCSR/matmult.c | MBCSR implementation of SpMV |
| src/VBR/matmult.c | VBR implementation of SpMV |
| tests/matmult.c | Test sparse matrix-vector multiply |
| matmult.h [code] | Sparse matrix-vector multiply implementation |
| matopts.c | |
| matopts.h [code] | Matrix options processing and generation |
| matpow.c | Sparse matrix-power-vector multiply implementation |
| matpow.h [code] | Sparse 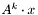 implementation implementation |
| matrix.c | Matrix handle implementation |
| matrix.h [code] | Matrix handle |
| tests/mattypes.c | Test the matrix type management module |
| mattypes.h [code] | Matrix type management routines |
| mattypes_internal.h [code] | Defines a matrix type record |
| memcpy.h [code] | Macros for typed block memory copy operations |
| methodtypes.h [code] | Defines a set of function pointer types for "standard" matrix type module methods |
| modcommon.h [code] | Definitions and structures common to dynamically shared modules |
| modloader.h [code] | Shared library module loader |
| BCSR/module.c | Block compressed sparse row (BCSR) module |
| BDIAG1/module.c | Single block diagonal (BDIAG1) module |
| CB/module.c | Generalized compressed sparse row (CB) implementation |
| CSC/module.c | Compressed sparse column (CSC) implementation |
| CSR/module.c | Compressed sparse row (CSR) module |
| DENSE/module.c | Generalized compressed sparse row (DENSE) implementation |
| GCSR/module.c | Generalized compressed sparse row (GCSR) implementation |
| MATTYPE_TEMPLATE/module.c | Modified block compressed sparse row (MATTYPE_TEMPLATE) module |
| MBCSR/module.c | Modified block compressed sparse row (MBCSR) module |
| VBR/module.c | Variable block row (VBR) implementation |
| BCSR/module.h [code] | Block compressed sparse row (BCSR) implementation |
| BDIAG1/module.h [code] | Block compressed sparse row (BDIAG1) implementation |
| CB/module.h [code] | |
| CSC/module.h [code] | Compressed sparse column implementation |
| CSR/module.h [code] | Compressed sparse row implementation |
| DENSE/module.h [code] | Dense column major format |
| GCSR/module.h [code] | Compressed sparse column implementation |
| MATTYPE_TEMPLATE/module.h [code] | Custom matrix module |
| MBCSR/module.h [code] | Modified block compressed sparse row (MBCSR) implementation |
| VBR/module.h [code] | Variable block row implementation |
| mregblock.h [code] | Implementation of the register blocking heuristic based on modified block compressed sparse row (MBCSR) format |
| multimalloc.c | Test OSKI multiple-malloc routine |
| oski_Tic.h [code] | Maps the default OSKI interface names to (int, complex_float) |
| oski_Tid.h [code] | Maps the default OSKI interface names to (int, double) |
| oski_Tis.h [code] | Maps the default OSKI interface names to (int, float) |
| oski_Tiz.h [code] | Maps the default OSKI interface names to (int, complex_double) |
| oski_Tlc.h [code] | |
| oski_Tld.h [code] | |
| oski_Tls.h [code] | |
| oski_Tlz.h [code] | |
| parse_opts.c | Parse command-line options |
| parse_opts.h [code] | Parse command-line options |
| perm.c | Permutations |
| perm.h [code] | Permutations |
| rand_util.c | Wrappers around the available random number generators |
| rand_util.h [code] | Wrappers around the available random number generators |
| readhbpat.c | Routine to read the pattern of a file stored in Harwell-Boeing format |
| readhbpat.h [code] | Defines utility routine to read a matrix pattern from a Harwell-Boeing formatted file |
| regblock.h [code] | Implementation of the basic register blocking heuristic for sparse matrix-vector multiply (as described in the Sparsity SC'02 and IJHPCA'04 papers), based on block compressed sparse row format |
| regprofheur.h [code] | Register blocking heuristic for general workloads |
| regprofmgr.h [code] | |
| regprofquery.h [code] | Workload query interface for register blocking heuristic |
| scalinfo.h [code] | Define the scalar types available to the library |
| simplelist.h [code] | Simple read-only, lockable, append-only list implementation |
| spmv_gencb.h [code] | |
| spmv_rsegdiag.h [code] | |
| spmv_tile_graph.h [code] | |
| spmv_tiled_bcsr.h [code] | Tiled BCSR format |
| spmv_ubcsr.h [code] | |
| spmv_vbr.h [code] | |
| sprintf.h [code] | Macros for typed block memory copy operations |
| stat.c | Implements some simple statistics gathering utilities |
| stat.h [code] | Provides some simple statistical utilities |
| structhint.c | Implementation of structural tuning hint data structure |
| structhint.h [code] | Structural hint implementation |
| symmrb.h [code] | Implementation of the register blocking heuristic for symmetric matrices, as described in the paper by Lee, et al., in ICPP'04, but extended to the Symmetric or Hermitian cases and based on MBCSR format |
| testvec.c | Code to generate vectors and vector views for testing and off-line benchmarking |
| testvec.h [code] | Test vector generation and checking |
| src/timer/timer.c | Timing module implementation |
| tests/timer.c | Tests timer module |
| timer.h [code] | Timing module |
| timing.h [code] | Timing wrapper macros |
| trace.h [code] | Implements a database for keeping track of kernel calls |
| trace_query.c | Implements a database system for tracking kernel calls |
| transpose.c | Implements a routine to transpose a CSR matrix |
| src/CSC/trisolve.c | CSC sparse triangular solve implementation |
| src/DENSE/trisolve.c | Calls xTRSV / xTRSM |
| src/trisolve.c | Sparse triangular solve implementation |
| tests/trisolve.c | Basic test of the CSR/CSC sparse triangular solve |
| trisolve.h [code] | Sparse triangular solve implementation |
| trsv.c | OSKI wrapper around the dense BLAS routine, xTRSV |
| tune.c | Tuning module implementation |
| tune.h [code] | Tuning interface |
| upper_conj.c | Conjugate sparse triangular solve implementation when the matrix is upper triangular |
| upper_conjtrans.c | Conjugate transposed sparse triangular solve implementation when the matrix is upper triangular and stored in CSR format |
| upper_normal.c | Non-transposed sparse triangular solve implementation when the matrix is upper triangular |
| upper_trans.c | Transposed sparse triangular solve implementation when the matrix is upper triangular and stored in CSR format |
| userconst.h [code] | Defines the constants available to the user in the official interface |
| vector.h [code] | Multivector view implementation |
| src/vecview.c | Multivector view implementation |
| tests/vecview.c | Test matrix handle creation |
| vecview.h [code] | Multivector view module |
| workload.c | Routines for simulating an arbitrary workload |
| workload.h [code] | Routines for simulating an arbitrary workload |
| xforms.c | Save/restore tuning transformations |
| xforms.h [code] | OSKI-Lua transformation module |
| xforms_internal.h [code] | This header file isolates the Lua-dependent aspects of the tuning transform implementation from the core OSKI code |
