Defines
Functions
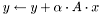 . .
. . 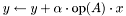 , where
, where 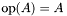 , on the fully blocked portion of
, on the fully blocked portion of 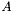 .
. 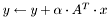 . . , where
. . , where 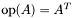 , on the fully blocked portion of . , where is stored in 8x3 MBCSR format.
, on the fully blocked portion of . , where is stored in 8x3 MBCSR format. Automatically generated by ./gen.sh on Wed Jun 8 15:52:53 PDT 2005.
#include <assert.h>
#include <oski/config.h>
#include <oski/common.h>
#include <oski/mangle.h>
#include <oski/vecview.h>
#include <oski/MBCSR/format.h>
#include <oski/MBCSR/module.h>
Defines | |
| #define | REGISTER register |
| Real-valued, so use explicit 'register' keyword. | |
| #define | MBCSR_MatMult_v1_aX_b1_xs1_ysX MANGLE_MOD_(MBCSR_MatMult_v1_aX_b1_xs1_ysX_8x3) |
| Mangled name for MBCSR_MatMult_v1_aX_b1_xs1_ysX. | |
| #define | MBCSR_MatMult_v1_aX_b1_xsX_ysX MANGLE_MOD_(MBCSR_MatMult_v1_aX_b1_xsX_ysX_8x3) |
| Mangled name for MBCSR_MatMult_v1_aX_b1_xsX_ysX. | |
| #define | MBCSR_MatTransMult_v1_aX_b1_xsX_ys1 MANGLE_MOD_(MBCSR_MatTransMult_v1_aX_b1_xsX_ys1_8x3) |
| Mangled name for MBCSR_MatTransMult_v1_aX_b1_xsX_ys1. | |
| #define | MBCSR_MatTransMult_v1_aX_b1_xsX_ysX MANGLE_MOD_(MBCSR_MatTransMult_v1_aX_b1_xsX_ysX_8x3) |
| Mangled name for MBCSR_MatTransMult_v1_aX_b1_xsX_ysX. | |
| #define | MBCSR_MatConjMult_v1_aX_b1_xs1_ysX MBCSR_MatMult_v1_aX_b1_xs1_ysX |
| See MBCSR_MatMult_v1_aX_b1_xs1_ysX(). | |
| #define | MBCSR_MatConjMult_v1_aX_b1_xsX_ysX MBCSR_MatMult_v1_aX_b1_xsX_ysX |
| See MBCSR_MatMult_v1_aX_b1_xsX_ysX(). | |
| #define | MatConjMult_v1 MatMult_v1 |
| Matrix times single-vector multiply in the conj case; see MatMult_v1(). | |
| #define | MatConjMult MatMult |
| See MatMult(). | |
| #define | MBCSR_MatHermMult_v1_aX_b1_xsX_ys1 MBCSR_MatTransMult_v1_aX_b1_xsX_ys1 |
| See MBCSR_MatTransMult_v1_aX_b1_xsX_ys1(). | |
| #define | MBCSR_MatHermMult_v1_aX_b1_xsX_ysX MBCSR_MatTransMult_v1_aX_b1_xsX_ysX |
| See MBCSR_MatTransMult_v1_aX_b1_xsX_ysX(). | |
| #define | MatHermMult_v1 MatTransMult_v1 |
| Matrix times single-vector multiply in the herm case; see MatTransMult_v1(). | |
| #define | MatHermMult MatTransMult |
| See MatTransMult(). | |
| #define | SubmatReprMult MANGLE_MOD_(SubmatReprMult_8x3) |
| Mangled name of exportable routine. | |
Functions | |
| void | MBCSR_MatMult_v1_aX_b1_xs1_ysX (oski_index_t M, oski_index_t d0, const oski_index_t *restrict bptr, const oski_index_t *restrict bind, const oski_value_t *restrict bval, const oski_value_t *restrict bdiag, oski_value_t alpha, const oski_value_t *restrict x, oski_value_t *restrict y, oski_index_t incy) |
| MBCSR implementation of . | |
| void | MBCSR_MatMult_v1_aX_b1_xsX_ysX (oski_index_t M, oski_index_t d0, const oski_index_t *restrict bptr, const oski_index_t *restrict bind, const oski_value_t *restrict bval, const oski_value_t *restrict bdiag, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t incx, oski_value_t *restrict y, oski_index_t incy) |
| MBCSR implementation of . | |
| static void | MatMult_v1 (oski_index_t M, oski_index_t d0, const oski_index_t *bptr, const oski_index_t *bind, const oski_value_t *bval, const oski_value_t *bdiag, oski_value_t alpha, const oski_value_t *x, oski_index_t incx, oski_value_t *y, oski_index_t incy) |
| Matrix times single-vector multiply in the normal case. | |
| static int | MatMult (const oski_submatMBCSR_t *A, oski_value_t alpha, const oski_vecview_t x_view, oski_vecview_t y_view) |
| Computes , where , on the fully blocked portion of . | |
| void | MBCSR_MatTransMult_v1_aX_b1_xsX_ys1 (oski_index_t M, oski_index_t d0, const oski_index_t *restrict bptr, const oski_index_t *restrict bind, const oski_value_t *restrict bval, const oski_value_t *restrict bdiag, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t incx, oski_value_t *restrict y) |
| MBCSR implementation of . | |
| void | MBCSR_MatTransMult_v1_aX_b1_xsX_ysX (oski_index_t M, oski_index_t d0, const oski_index_t *restrict bptr, const oski_index_t *restrict bind, const oski_value_t *restrict bval, const oski_value_t *restrict bdiag, oski_value_t alpha, const oski_value_t *restrict x, oski_index_t incx, oski_value_t *restrict y, oski_index_t incy) |
| MBCSR implementation of . | |
| static void | MatTransMult_v1 (oski_index_t M, oski_index_t d0, const oski_index_t *bptr, const oski_index_t *bind, const oski_value_t *bval, const oski_value_t *bdiag, oski_value_t alpha, const oski_value_t *x, oski_index_t incx, oski_value_t *y, oski_index_t incy) |
| Matrix times single-vector multiply in the trans case. | |
| static int | MatTransMult (const oski_submatMBCSR_t *A, oski_value_t alpha, const oski_vecview_t x_view, oski_vecview_t y_view) |
| Computes , where , on the fully blocked portion of . | |
| int | SubmatReprMult (const oski_submatMBCSR_t *A, oski_matop_t opA, oski_value_t alpha, const oski_vecview_t x_view, oski_vecview_t y_view) |
| Computes , where is stored in 8x3 MBCSR format. | |
 1.4.6
1.4.6