|
The BeBOP group is broadly interested in understanding software
performance tuning issues, and the interaction or implications
for hardware design.
Among our general interests are
-
the interaction between application software, compilers,
and hardware
-
managing trade-offs among the various measures of performance,
such as speed, accuracy, power, storage, ...
-
automating the performance tuning process, starting with
the computational kernels which dominate application
performance in scientific computing and information
retrieval
-
performance modeling and evaluation of future computer
architectures
See the links below for detailed project information and status.
Principal Investigators
Affiliated Researchers
Graduate Students
Previous Participants
- 2017 Householder Prize - Edgar Solomonik
- 2017 Householder Prize Finalist - Erin Carson
- 2017 election to American Academy of Arts and Sciences - Katherine Yelick
- 2017 election to National Academy of Engineering - Katherine Yelick
- 2017 induction to Alameda County Women's Hall of Fame - Katherine Yelick
- 2017 ACM-IEEE CS George Michael Memorial HPC Fellowship - Yang You
- 2016 SIAG on Supercomputing Best Paper Prize - James Demmel, Laura Grigori, Mark Hoemmen, and Julien Langou
- 2015 IPDPS Best Paper Award - Yang You, James Demmel, Kenneth Czechowski, Le Song, and Richard Vuduc
- 2015 Fellow of the American Association for the Advancement of Science - James Demmel
- 2014 ACM Paris Kanellakis Theory and Practice Award - James Demmel
- 2014 Paper Optimizing Matrix Multiply using PHiPAC: a Portable High-Performance, ANSI C Coding Methodology
selected for inclusion in "25 years of International Conference on Supercomputing,"
as one of the 35 most influential papers published in that conference from 1987-2011
(out of about 1800 papers total) - Jeff Bilmes, Krste Asanovic, Chee-Whye Chin, James Demmel
- 2014 CACM Research Highlight
- Grey Ballard, James Demmel, Olga Holtz, Oded Schwartz
- 2014 David J. Sakrison Memorial Prize - Edgar Solomonik
- 2014 ACM Doctoral Dissertation Award, 2013- Honorable Mention - Grey Ballard
- 2013 2013-2014 Athena lecturer - Katherine Yelick
- 2013 ACM Fellow - Katherine Yelick
- 2013 IPDPS Charles Babbage Award - James Demmel
- 2013 ACM-IEEE CS George Michael Memorial HPC Fellowship - Edgar Solomonik
- 2013 IPDPS
Best Paper Award - Grey Ballard, Dulceneia Becker, James Demmel, Jack Dongarra, Alex Druinsky, Inon Peled, Oded Schwartz, Sivan Toledo, Ichitaro Yamazaki
- 2012 C.V. Ramamoorthy Distinguished Research Award - Grey Ballard
- 2012 SIAM SIAG/LA Prize (for the years 2009-2011) - Grey Ballard, James Demmel, Olga Holtz, Oded Schwartz
- 2011 Election to National Academy of Sciences - James Demmel
- 2011 Euro-Par Distinguished Paper Prize - Edgar Solomonik and James Demmel
- 2011 SPAA Best Paper Award - Grey Ballard, James Demmel, Olga Holtz, Oded Schwartz
- 2010 IEEE Sidney Fernbach Award - James Demmel
- 2004 ICPP Best Paper Prize - James Demmel, Benjamin Lee, Richard Vuduc, Katherine Yelick
Download BibTeX entries for these papers and reports.
Year:
2017
| 2016
| 2015
| 2014
| 2013
| 2012
| 2011
| 2010
| 2009
| 2008
| 2007
| 2006
| 2005
| 2004
| 2003
| 2002
| 2001
-
Paper: Scaling Deep Learning on GPU and Knights Landing Clusters
(Supercomputing'17, November 2017)
Yang You, Aydın Buluç, and James Demmel
PDF
-
Paper: Runtime Data Layout Scheduling for Machine Learning Dataset
(International Conference on Prallel Processing '17, August 2017)
Yang You and James Demmel
PDF
-
Paper: Performance Characterization of De Novo Genome Assembly on Leading Parallel Systems
(Euro-Par'17, August 2017)
Marquita Ellis, Evangelos Georganas, Rob Egan, Steven Hofmeyr, Aydın Buluç, Brandon Cook, Leonid Oliker and Katherine Yelick
PDF
-
Tech Report: Communication-Avoiding Optimization Methods for Massive-Scale Graphical Model Structure Learning
(arXiv:1710.10769, October 2017)
Penporn Koanantakool, Alnur Ali, Ariful Azad, Aydın Buluç, Dmitriy Morozov, Sang-Yun Oh, Leonid Oliker, and Katherine Yelick
PDF
-
Tech Report: Avoiding Communication in Proximal Methods for Convex Optimization Problems
(arXiv:1710.08883, October 2017)
Saeed Soori, Aditya Devarakonda, James Demmel, Mert Gurbuzbalaban, and Maryam Mehri Dehnavi
PDF
-
Tech Report: Scaling SGD Batch Size to 32K for ImageNet Training
(UCB/EECS-2017-156, September 2017)
Yang You, Igor Gitman, and Boris Ginsburg
PDF
-
Tech Report: ImageNet Training in Minutes
(arXiv:1709.05011, November 2017)
Yang You, Zhao Zhang, Cho-Jui Hseih, James Demmel and Kurt Keutzer
PDF
-
Paper: Exploiting multiple levels of parallelism in sparse matrix-matrix multiplication
(SIAM Journal on Scientific Computing (SISC), 38(6):C624-C651, 2016)
Ariful Azad, Grey Ballard, Aydın Buluç, James Demmel, Laura Grigori, Oded Schwartz, Sivan Toledo, and Samuel Williams
PDF
-
Paper: Design and Implementation of a Communication-Optimal Classifier for Distributed Kernel Support Vector Machines
(IEEE Transactions on Parallel and Distributed Systems 2016)
Yang You, James Demmel, Kent Czechowski, Le Song, and Rich Vuduc
PDF
-
Paper: Asynchronous Parallel Greedy Coordinate Descent
(Conference on Neural Information Processing Systems 2016)
Yang You, XiangRu Lian, Ji Liu, Hsiang-Fu Yu, Inderjit S. Dhillon, James Demmel, and Cho-Jui Hsieh
PDF
-
Ph.D. Thesis: Scalable Parallel Algorithms for Genome Analysis
(Computer Science Division, U.C. Berkeley, August 2016)
Evangelos Georganas
PDF
- Paper: Communication-Avoiding Parallel Sparse-Dense Matrix-Matrix Multiplication
(Proceedings of the 30th IEEE International Parallel & Distributed Processing Symposium (IPDPS'16), May 2016)
Penporn Koanantakool, Ariful Azad, Aydın Buluç, Dmitriy Morozov, Sang-Yun Oh, Leonid Oliker, and Katherine Yelick
PDF
- Paper: Write-Avoiding Algorithms
(Proceedings of the 30th IEEE International Parallel & Distributed Processing Symposium (IPDPS'16), May 2016)
Erin Carson, James Demmel, Laura Grigori, Nick Knight, Penporn Koanantakool, Oded Schwartz and Harsha Vardhan Simhadri
PDF (see also
UCB/EECS-2015-163)
- Paper: Matrix factorizations at scale: A comparison of scientific data analytics in spark and C+ MPI using three case studies
(Proceedings of the IEEE International Conference on Big Data (Big Data 2016), December 2016)
Alex Gittens, Aditya Devarakonda, Evan Racah, Michael Ringenburg, Lisa Gerhardt, Jey Kottalam, Jialin Liu, Kristyn Maschhoff, Shane Canon, Jatin Chhugani, Pramod Sharma, Jiyan Yang, James Demmel, Jim Harrell, Venkat Krishnamurthy, and Michael W. Mahoney
PDF
- Tech Report: Avoiding communication in primal and dual block coordinate descent methods
(arXiv:1612.04003, May 2017)
Aditya Devarakonda, Kimon Fountoulakis, James Demmel, and Michael W. Mahoney
PDF
-
Paper: HipMer: An Extreme-Scale De Novo Genome Assembler
(Supercomputing'15, November 2015)
Evangelos Georganas, Aydın Buluç, Jarrod Chapman, Steven Hofmeyr, Chaitanya Aluru, Rob Egan, Leonid Oliker, Daniel Rokhsar and Katherine Yelick
PDF
-
Paper: merAligner: A Fully Parallel Sequence Aligner
(29th IEEE International Parallel & Distributed Processing Symposium (IPDPS'15))
Evangelos Georganas, Aydın Buluç, Jarrod Chapman, Leonid Oliker, Daniel Rokhsar and Katherine Yelick
PDF
-
Paper: A whole-genome shotgun approach for assembling and anchoring the hexaploid bread wheat genome
(Genome Biology 2015, 16:26)
Jarrod A. Chapman, Martin Mascher, Aydın Buluç, Kerrie Barry, Evangelos Georganas, Adam Session, Veronika Strnadova, Jerry Jenkins, Sunish Sehgal, Leonid Oliker, Jeremy Schmutz, Katherine A. Yelick, Uwe Scholz, Robbie Waugh, Jesse A. Poland, Gary J. Muehlbauer, Nils Stein and Daniel S. Rokhsar
PDF
-
Tech Report: Efficient Reproducible Floating Point Summation and BLAS
(UCB/EECS-2015-229, Dec 2015)
Willow Ahrens, Hong Diep Nguyen, and James Demmel
PDF
- Ph.D. Thesis: Communication-Optimal Loop Nests
(Computer Science Division, U.C. Berkeley, August 2015)
Nicholas Knight
PDF
- Ph.D. Thesis: Communication-Avoiding Krylov Subspace Methods in Theory and Practice
(Computer Science Division, U.C. Berkeley, August 2015)
Erin Carson
PDF
- Paper: Reconstructing Householder Vectors from Tall-Skinny QR
J. Par. Distr. Comp. Aug 2015
(available at
dx.doi.org/10.1016/j.jpdc.2015.06.003)
(see also
UCB/EECS-2013-175)
Grey Ballard, James Demmel, Laura Grigori, Mathias Jacquelin, and Hong Diep Nguyen
- Paper: Accuracy of the s-step Lanczos method for the symmetric eigenproblem
SIAM J. Mat. Anal. Appl., v. 36, n. 2, pp 793-819, 2015
Erin Carson and James Demmel
PDF
(see also
UCB/EECS-2014-165)
-
Paper: Parallel Reproducible Summation
IEEE Transactions on Computers, v. 64, i. 7, July 2015 (appeared August 2014)
James Demmel and Hong Diep Nguyen
DOI: 10.1109/TC.2014.2345391
-
Paper: Extending Access to HPC Skills Through a Blended On-line Course
S. Gordon, J. Demmel, L. Destefano and L. Rivera
To appear in Proc. of Conference on Extreme Science and Engineering
Discovery Environment (XSEDE'15), July 2015
PDF
-
Paper: Reproducible Tall-Skinny QR Factorization
N.-D. Nguyen and James Demmel
to appear in 22nd IEEE Symp. Computer Arithmetic (ARITH'22),
IEEE Computer Society, Jun 22-24, 2015
PDF
-
Paper: CA-SVM: Communication-avoiding support vector machines on clusters
International Parallel & Distributed Processing Symposium (IPDPS'15), May 2015
Yang You, James Demmel, Kenneth Czechowski, Le Song, Richard Vuduc
[Best Paper Award]
PDF
(see also
UCB/EECS-2015-9)
-
Paper: Communication Avoiding Rank Revealing QR Factorization with Column Pivoting
SIAM J. Mat. Anal. Appl., v. 36, n. 1, pp 55-89, 2015
James Demmel, Laura Grigori, Ming Gu and Hua Xiang
PDF
(see also
UCB/EECS-2013-46)
-
Tech Report: FRPA: A Framework for Recursive Parallel Algorithms
(UCB/EECS-2015-28, May 2015)
David Eliahu, Omer Spillinger, Armando Fox and James Demmel
PDF
-
Tech Report: Matrix Multiplication Algorithm Selection with Support Vector Machines
(UCB/EECS-2015-29, May 2015)
Omer Spillinger, David Eliahu, Armando Fox and James Demmel
PDF
-
Tech Report: Avoiding Communication in the Lanczos Bidiagonalization Routine and Associated Least Squares QR Solver
(UCB/EECS-2015-15, April 2015)
Erin Carson
PDF
-
Paper: Avoiding Communication in Successive Band Reduction
ACM Trans. Parallel Computing, v. 1, i. 2, Jan 2015
Grey Ballard, James Demmel and Nicholas Knight
PDF
(see also
UCB/EECS-2013-131)
-
Tech Report: Communication lower bounds for tensor contraction algorithms
Technical Report, ETH Zurich, Jan 2015
Edgar Solomonik, James Demmel and Torsten Hoefler
PDF
-
Tech Report: Contracting symmetric tensors using fewer multiplications
Technical Report, ETH Zurich, Jan 2015
Edgar Solomonik and James Demmel
PDF
-
Paper: Parallel De Bruijn Graph Construction and Traversal for De Novo Genome Assembly
(Supercomputing'14, November 2014)
Evangelos Georganas, Aydın Buluç, Jarrod Chapman, Leonid Oliker, Daniel Rokhsar and Katherine Yelick
PDF
-
Paper: Architecting an autograder for parallel code
(Proceedings of the 2014 Annual Conference on Extreme Science and Engineering Discovery Environment (XSEDE'14), July 2014)
Razvan Carbunescu, Aditya Devarakonda, James Demmel, Steven Gordon, Jay Alameda, and Susan Mehringer
PDF
- Paper: Scalable Multimedia Content Analysis on Parallel Platforms Using Python
(ACM Transactions on Multimedia Computing, Communications and Applications (TOMM'14) February 2014)
Ekaterina Gonina, Gerald Friedland, Eric Battenberg, Penporn Koanantakool, Michael Driscoll, Evangelos Georganas, Kurt Keutzer
PDF
-
Master's Thesis: Automatic Structure Detection in LAPACK
(Computer Science Division, U.C. Berkeley, December 2014)
Razvan Carbunescu
PDF
-
Paper: A Computation- And Communication-Optimal Parallel Direct 3-Body Algorithm
Supercomputing'14, November 2014
Penporn Koanantakool and Katherine Yelick
PDF (2MB)
-
Ph.D. Thesis: Bounds on the Energy Consumption of Computational Kernels
(Computer Science Division, U.C. Berkeley, October 2014)
Andrew Gearhart
PDF
- Paper: Exploiting data sparsity in parallel matrix powers computations
Proceedings of 10th Intern. Conf. on Parallel Processing and Applied Mathematics (PPAM'13),
R. Wyrzykowski, J. Dongarra, K. Karczewski, and J. Waniewski, eds.,
Lecture Notes in Computer Science, Springer Berlin Heidelberg, 2014, pp.15-25.
Erin Carson, James Demmel, Nicholas Knight
PDF
(see also
UCB/EECS-2013-47)
-
Paper: Communication-Avoiding Symmetric-Indefinite Factorization
SIAM J. Mat. Anal. Appl., v. 35, i. 4, 2014
Grey Ballard, Dulceneia Becker, James Demmel, Jack Dongarra, Alex Druinsky, Inon Peled, Oded Schwartz,
Sivan Toledo, and Ichitaro Yamazaki
PDF
(see also
UCB/EECS-2013-127)
-
Tech report: Accuracy of the s-step Lanczos method for the symmetric eigenproblem
(UCB/EECS-2014-165, September 2014)
Erin Carson and James Demmel
PDF
-
Ph.D. Thesis: Provably Efficient Algorithms for Numerical Tensor Algebra
(Computer Science Division, U.C. Berkeley, August 2014)
Edgar Solomonik
PDF
-
Tech report: Contention Bounds for Combinations of Computation Graphs and Network Topologies
(UCB/EECS-2014-147, August 2014)
Presented at CSC'14: 6th SIAM Workshop on Combinatorial Scientific Computing, July 2014
Grey Ballard, James Demmel, Andrew Gearhart, Benjamin Lipshitz, Oded Schwartz and Sivan Toledo
PDF
- Paper: Architecting an Autograder for Parallel Code
Proc. of Conference on Extreme Science and Engineering
Discovery Environment (XSEDE'14), July 2014
Jay Alameda, Razvan Carbunescu, James Demmel, Aditya Devarakonda, Steven Gordon, and Susan Mehringer
PDF
- Paper: Tradeoffs between synchronization, communication and work
in parallel linear algebra computations
Proceedings of the 26th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA'14)
Edgar Solomonik, Erin Carson, Nicholas Knight, and James Demmel
[Invited to appear in ACM Trans. Par. Comp.]
PDF
(see also
UCB/EECS-2014-8)
-
Paper: A massively parallel tensor contraction framework for coupled-cluster computations
Journal of Parallel and Distributed Computing, June 2014.
Edgar Solomonik, Devin Matthews, Jeff R. Hammond, John F. Stanton, and James Demmel.
PDF
(see also
UCB/EECS-2014-143)
-
Paper: An efficient deflation technique for the Communication-Avoiding Conjugate Gradient method
ETNA (Electronic Transactions on Numerical Analysis), 23 (2014), pp. 125-141
Erin Carson, Nicholas Knight and James Demmel
PDF
-
Paper: Communication lower bounds and optimal algorithms for numerical linear algebra
Acta Numerica. Cambridge University Press, 23, 1-155, 2014.
Grey Ballard, Erin Carson, James Demmel, Mark Hoemmen, Nick Knight, and Oded Schwartz.
[Invited]
PDF
- Paper: Reconstructing Householder Vectors from Tall-Skinny QR
International Parallel & Distributed Processing Symposium (IPDPS'14), May 2014
Grey Ballard, James Demmel, Laura Grigori, Mathias Jacquelin, Hong Diep Nguyen, Edgar Solomonik
PDF
(see also
UCB/EECS-2013-175)
- Paper: s-Step Krylov Subspace Methods as Bottom Solvers for Geometric Multigrid
International Parallel & Distributed Processing Symposium (IPDPS'14), May 2014
Samuel Williams, Mike Lijewski, Ann Almgren, Brian Van Straalen, Erin Carson, Nicholas Knight, and James Demmel
PDF
-
Tech report: Error analysis of the s-step Lanczos method in finite precision
(UCB/EECS-2014-55, May 2014)
Erin Carson and James Demmel
PDF
-
Tech report: Analysis of the finite precision s-step biconjugate gradient method
(UCB/EECS-2014-18, March 2014)
Erin Carson and James Demmel
PDF
-
Paper: A Residual Replacement Strategy for Improving the Maximum Attainable Accuracy of s-step Krylov Subspace Methods
SIAM J. Matrix Anal. Appl., 35(1), pp. 22-43.
Erin Carson and James Demmel
PDF
(see also
UCB/EECS-2012-197)
-
Paper: Communication Costs of Strassen's Matrix Multiplication
Comunications of the ACM, v. 57, n. 02, pp 107-114, Feb 2014
Grey Ballard, James Demmel, Olga Holtz, and Oded Schwartz
[Invited Research Highlight]
PDF
-
Tech report: Tradeoffs between synchronization, communication, and work in parallel linear algebra computations
(UCB/EECS-2014-8, January 2014)
Edgar Solomonik, Erin Carson, Nicholas Knight, and James Demmel
PDF
-
Paper: Avoiding Communication in Nonsymmetric Lanczos-Based Krylov Subspace Methods
SIAM J. Sci. Comput., 35(5), pp. S42-S61.
Erin Carson, Nicholas Knight, and James Demmel
PDF
(see also
UCB/EECS-2011-93)
- Paper: LU Factorization with Panel Rank Revealing Pivoting and Its Communication Avoiding Version
SIAM J. Mat. Anal. Appl. v. 34, n 3, 2013
Amal Khabou, James Demmel, Laura Grigori, and Ming Gu
PDF
(see also
UCB/EECS-2012-15)
- Paper: Precimonious: Tuning assistant for floating-point precision
Proc. of Supercomputing'13
Cindy Rubio-Gonzalez, Cuong Nguyen, Hong Diep Nguyen, James Demmel, William Kahan,
Koushik Sen, David Bailey, Costin Iancu, and David Hough
PDF
-
Tech report: Reconstructing Householder Vectors from Tall-Skinny QR
(UCB/EECS-2013-175, October 2013)
Grey Ballard, James Demmel, Laura Grigori, Mathias Jacquelin, Hong Diep Nguyen, and Edgar Solomonik
PDF
- Paper: Direct QR factorizations for tall-and-skinny matrices in MapReduce architectures
2013 IEEE Intern. Conf. on Big Data (IEEE BigData 2013), Oct 2013, Santa Clara, CA
Austin Benson, James Demmel and David Gleich
PDF
-
Paper: Communication Efficient Gaussian Elimination with Partial Pivoting using a Shape Morphing Data Layout
Proceedings of the 25th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA'13),
pp. 232-241, 2013
Grey Ballard, James Demmel, Ben Lipshitz, Oded Schwartz, and Sivan Toledo
PDF
(see also
UCB/EECS-2013-12)
-
Paper: Communication Optimal Parallel Multiplication of Sparse Random Matrices
Proceedings of the 25th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA'13), pp.
222-231, 2013
Grey Ballard, Aydın Buluç, James Demmel, Laura Grigori, Ben Lipshitz Oded Schwartz, and Sivan Toledo
PDF
(see also
UCB/EECS-2013-13)
-
Paper: Implementing a Blocked Aasen's Algorithm with a Dynamic Scheduler on Multicore Architectures
Proceedings of the IEEE International Parallel & Distributed Processing Symposium (IPDPS'13), 2013
Grey Ballard, Dulceneia Becker, James Demmel, Jack Dongarra, Alex Druinsky, Inon Peled, Oded Schwartz,
Sivan Toledo, and Ichitaro Yamazaki
[IPDPS'13 Best Paper Award]
PDF
- Tech Report: Communication-Avoiding Symmetric-Indefinite Factorization
(UCB/EECS-2013-127)
Grey Ballard, Dulceneia Becker, James Demmel, Jack Dongarra, Alex
Druinsky, Inon Peled, Oded Schwartz, Sivan Toledo, Ichitaro Yamazaki
PDF
-
Paper: Perfect Strong Scaling Using No Additional Energy
Proceedings of the IEEE International Parallel & Distributed Processing Symposium (IPDPS'13), 2013
James Demmel, Andrew Gerhart, Ben Lipshitz, and Oded Schwartz
PDF
(see also
UCB/EECS-2012-126)
-
Paper: Communication-Optimal Parallel Recursive Rectangular Matrix Multiplication
Proceedings of the IEEE International Parallel & Distributed Processing Symposium (IPDPS'13), 2013
James Demmel, David Eliahu, Armando Fox, Shoaib Kamil, Ben Lipshitz, Oded Schwartz, and Omer Spillinger
PDF
(see also
UCB/EECS-2012-205)
- Ph.D. Thesis: Avoiding communication in dense linear algebra
(Computer Science Division, U.C. Berkeley, August 2013)
Grey Ballard
PDF
- Tech Report: Avoiding Communication in Successive Band Reduction
EECS Technical Report No. UCB/EECS-2013-131, July 11, 2013
Grey Ballard, James Demmel, Nicholas Knight
PDF
- Tech Report: An arithmetic complexity lower bound for computing rational functions, with applications to linear algebra
EECS Technical Report No. UCB/EECS-2013-126, July 1, 2013
James Demmel
PDF
- Paper: Providing a supported online course on parallel computing (extended abstract)
Proc. of Conference on Extreme Science and Engineering
Discovery Environment (XSEDE'13), July 2013
Jay Alameda, Razvan Carbunescu, James Demmel, Steven Gordon, and Susan Mehringer
PDF
- Tech Report: Communication Lower Bounds and Optimal Algorithms for Programs That Reference Arrays — Part 1
EECS Technical Report No. UCB/EECS-2013-61, May 14, 2013
Michael Christ, James Demmel, Nicholas Knight, Thomas Scanlon, and Katherine Yelick
PDF (revised version),
PDF (original)
- Paper: Communication-Avoiding Krylov Techniques on Graphics Processing Units
IEEE Trans. on Magnetics, v. 49, n. 5, May 2013
Maryam Mehri Dehnavi, James Demmel, Dennis Giannacopoulos, Yousef El-Kurdi
PDF
- Paper: A Communication-Optimal N-Body Algorithm for Direct Interactions
In Proceedings of 27th IEEE International Parallel & Distributed Processing Symposium
(IPDPS'13) 2013
Michael Driscoll, Evangelos Georganas, Penporn Koanantakool, Edgar Solomonik and Katherine Yelick
PDF
- Tech Report: Exploiting data sparsity in parallel matrix powers computations
EECS Technical Report No. UCB/EECS-2013-47, May 3, 2013
Erin Carson, James Demmel, Nicholas Knight
PDF
(To appear in Proceedings of PPAM 2013, Springer LNCS)
- Tech Report: Communication Avoiding Rank Revealing QR Factorization with Column Pivoting
EECS Technical Report No. UCB/EECS-2013-46
James Demmel, Laura Grigori, Ming Gu, and Hua Xiang
PDF
- Paper: Fast Reproducible Floating-Point Summation
21st IEEE Symposium on Computer Arithmetic, April 2013
James Demmel and Hong Diep Nguyen
PDF
- Paper: Numerical Accuracy and Reproducibility at ExaScale
21st IEEE Symposium on Computer Arithmetic, April 2013
James Demmel and Hong Diep Nguyen
PDF
- Paper: Cyclops Tensor Framework: reducing communication and eliminating load
imbalance in massively parallel contractions
In Proceedings of 27th IEEE International Parallel & Distributed Processing Symposium (IPDPS'13) 2013
Edgar Solomonik, Devin Matthews, Jeff Hammond, and James Demmel
PDF
(see also
UCB/EECS-2013-11)
- Paper: Minimizing communication in all-pairs shortest-paths
In Proceedings of 27th IEEE International Parallel & Distributed Processing Symposium (IPDPS'13) 2013
Edgar Solomonik, Aydın Buluç, and James Demmel
PDF
(see also
UCB/EECS-2013-10)
- Paper:
Communication-optimal Parallel and Sequential QR and LU Factorizations
SIAM J. Sci. Comput., 34(1), A206-A239, February 2012
James Demmel, Laura Grigori, Mark Hoemmen, and Julien Langou
[SIAG on Supercomputing Best Paper Prize]
PDF
(see also
UCB/EECS-2008-89)
- Paper: Fast l1-SPIRiT Compressed Sensing Parallel Imaging MRI:
Scalable Parallel Implementation and Clinically Feasible Runtime
IEEE Trans. Medical Imaging, v. 31, i. 6, pp 1250-1262, 2012
Marc Alley, Mark Murphy, Kurt Keutzer, Shreyas Vasanawala, James Demmel, and Michael Lustig
PDF
- Tech Report: Autotuning Sparse Matrix-Vector Multiplication for Multicore
(UCB/EECS-2012-215, November 2012)
Jong-Ho Byun, Richard Lin, Katherine A. Yelick and James Demmel
PDF (2223k)
- Paper: Graph Expansion and Communication Costs of Fast
Matrix Multiplication
In Journal of the ACM, 2012
Grey Ballard, James Demmel, Olga Holtz, and Oded Schwartz
[Invited to appear as CACM Research Highlight]
PDF
(228k)
- Paper:
Graph Expansion Analysis for Communication Costs of Fast Rectangular Matrix
Multiplication
Proceedings of the 1st Mediterranean Conference on Algorithms (MedAlg'12), Dec 2012
Appeared in Lecture Notes in Computer Science, Springer, v. 7659, pp 13-36
Grey Ballard, James Demmel, Olga Holtz, Benjamin Lipshitz, Oded Schwartz
PDF
(see also
UCB/EECS-2012-194)
- Paper: Communication Avoiding and Overlapping for Numerical Linear Algebra
November 2012
In Proceedings of 2012 International
Conference for High Performance Computing, Networking, Storage and
Analysis (SC '12)
Evangelos Georganas, Jorge González-Domínguez, Edgar Solomonik, Yili Zheng, Juan Touriño and Katherine Yelick
PDF (520k)
- Paper: Communication-Avoiding Parallel Strassen: Implementation and Performance
November 2012
In Proceedings of 2012 International
Conference for High Performance Computing, Networking, Storage and
Analysis (SC '12)
Grey Ballard, James Demmel, Benjamin Lipshitz, and Oded Schwartz
PDF
(see also
UCB/EECS-2012-90)
- Tech Report: Communication-Optimal Parallel Recursive Rectangular Matrix Multiplication
(UCB/EECS-2012-205)
James Demmel, David Eliahu, Armando Fox, Shoaib Kamil, Benjamin Lipshitz, Oded Schwartz, Omer Spillinger
PDF
- Tech Report: A Residual Replacement Strategy for Improving the Maximum Attainable Accuracy of s-step Krylov Subspace Methods
(UCB/EECS-2012-197, September 2012)
Erin Carson and James Demmel
PDF
- Paper: Communication-Optimal Parallel Algorithm for Strassen's Matrix Multiplication
Proceedings of the 24th Annual ACM Symposium on Parallelism in Algorithms and Architectures (SPAA'12) (June 2012)
Grey Ballard, James Demmel, Olga Holtz, Benjamin Lipshitz, Oded Schwartz
PDF
(see also
UCB/EECS-2012-32)
- Paper:
Strong Scaling of Matrix Multiplication Algorithms and
Memory-Independent Communication Lower Bounds (Brief Announcement)
Proceedings of the 24th Annual ACM Symposium on Parallelism in Algorithms and Architectures (SPAA'12) (June 2012)
Grey Ballard, James Demmel, Olga Holtz, Benjamin Lipshitz, and Oded Schwartz
PDF
(see also
UCB/EECS-2012-31)
- Tech Report: Communication bounds for heterogeneous architectures
(June 2012)
Grey Ballard, James Demmel, and Andrew Gearhart
PDF (248k)
- Tech Report: Instrumenting Linear Algebra Energy Consumption via On-chip Energy Counters
(UCB/EECS-2012-168, June 2012)
James Demmel and Andrew Gearhart
PDF
- Tech Report: Perfect strong scaling using no additional energy
(UCB/EECS-2012-126, May 2012)
James Demmel, Andrew Gearhart, Oded Schwartz and Benjamin Lipshitz
PDF
- Tech Report: Communication Avoiding and Overlapping for Numerical Linear Algebra
(UCB/EECS-2012-65, May 2012)
Evangelos Georganas, Jorge González-Domínguez, Edgar Solomonik, Yili Zheng, Juan Touriño and Katherine Yelick
PDF
- Tech Report: Sequential Communication Bounds for Fast Linear Algebra
(UCB/EECS-2012-36, March 2012)
Grey Ballard, James Demmel, Olga Holtz, Oded Schwartz
PDF
- Tech Report: A preliminary analysis of Cyclops Tensor Framework
(UCB/EECS-2012-29, March 2012)
Edgar Solomonik, Jeff Hammond, and James Demmel
PDF
- Paper: Communication Avoiding Successive Band Reduction
ACM Symposium on Principles and Practice of Parallel Programming (PPoPP), February 2012.
Grey Ballard, Nicholas Knight, and James Demmel
PDF (1357k)
- Tech Report: Matrix multiplication on multidimensional torus networks
VECPAR'12, Springer Lecture Notes in Computer Science (LCNS), Kobe, Japan, July 2012
Edgar Solomonik and James Demmel
PDF
(see also
UCB/EECS-2012-28)
- Tech Report: LU Factorization with Panel Rank Revealing Pivoting and Its Communication Avoiding Version
(UCB/EECS-2012-15, January 2012)
Amal Khabou, James Demmel, Laura Grigori, and Ming Gu
PDF (689k)
- Tech Report: Avoiding Communication in Two-Sided Krylov Subspace Methods
(UCB/EECS-2011-93, August 2011)
Erin Carson, Nicholas Knight, and James Demmel
PDF (793k)
- Paper: Improving communication performance in dense linear algebra via topology aware collectives
Supercomputing'11 (Nov 2011)
Edgar Solomonik, Abhinav Bhatele, and James Demmel
PDF
(see also
UCB/EECS-2011-92)
- Paper: Reduced-Bandwidth Multithreaded Algorithms for Sparse Matrix-Vector Multiplication
International Parallel & Distributed Processing Symposium (IPDPS'11), May 2011
Aydın Buluç, Samuel Williams, Lenny Oliker, James Demmel
PDF (791k)
- Paper: Graph Expansion and Communication Costs of Fast Matrix Multiplication
ACM Symposium on Parallelism in Algorithms and Architectures (SPAA'11), June 2011
Grey Ballard, James Demmel, Olga Holtz, and Oded Schwartz
[SPAA Best Paper Award]
PDF (228k)
- Tech Report: Communication-optimal parallel 2.5D matrix multiplication and LU factorization algorithms
(UCB/EECS-2011-10, February 2011)
Edgar Solomonik and James Demmel
[Euro-Par Distinguished Paper Award]
PDF (700k)
- Tech report: Minimizing Communication in Numerical Linear Algebra
(UCB/EECS-2011-15, February 2011)
Grey Ballard, James Demmel, Olga Holtz, Oded Schwartz
[SIAM SIAG/LA Prize]
PDF (560k) (2011 updated version)
- Paper: Communication-Optimal Parallel and Sequential
Cholesky Decomposition
SIAM Journal on Scientific Computing (SISC), December 2010
Grey Ballard, James Demmel, Olga Holtz, and Oded Schwartz
PDF (463k)
*Conference version published in SPAA 2009
- Tech Report: Minimizing Communication for Eigenproblems and the Singular Value Decomposition
(UCB/EECS-2011-14, February 2011)
Grey Ballard, James Demmel, and Ioana Dumitriu
PDF (852k)
- Tech Report: Communication-Avoiding QR Decomposition for GPUs
(UCB/EECS-2010-131, October 2010)
Michael Anderson, Grey Ballard, James Demmel, and Kurt Keutzer
PDF (2.3M)
- Paper: Brief Announcement: Lower Bounds on Communication for Sparse Cholesky Factorization of a Model Problem
Symposium on Parallelism in Algorithms and Architectures (SPAA 2010), June 2010
Laura Grigori, Pierre-Yves David, James Demmel, Sylvain Peyronnet
PDF (99.5k)
- Tech Report: CALU: A Communication Optimal LU Factorization Algorithm
(UCB/EECS-2010-29,March 2010)
James Demmel, Laura Grigori, Hua Xiang
PDF (428k)
- Ph.D. Thesis: Communication-avoiding Krylov subspace methods
(Computer Science Division, U.C. Berkeley, May 2010)
Mark Hoemmen
PDF (4.2M)
- Ph.D. Thesis: Auto-tuning Stencil Codes for Cache-Based
Multicore Platforms
(Computer Science Division, U.C. Berkeley, December 2009)
Kaushik Datta
PDF (3.1M)
Talk Slides: PPTX (4.1M) -or-
PDF (3.3M)
- Ph.D. Thesis: Automatically Tuning Collective Communication for One-Sided Programming Models
(Computer Science Division, U.C. Berkeley, December 2009)
Rajesh Nishtala
PDF (4.7M)
Talk Slides: PPTX (5.9M) -or-
PDF (8.2M)
- Paper: A Methodology for Domain-Optimized Power-Efficient Supercomputing
(In Proc. of SC09, November, 2009)
Marghoob Mohiyuddin, Mark Murphy, Leonid Oliker, John Shalf, John Wawrzynek, and Sam Williams
PDF (950k)
Talk slides:PDF (3.3M)
- Paper: Minimizing Communication in Sparse Matrix Solvers
(In Proc. of SC09, November, 2009)
Marghoob Mohiyuddin, Mark Hoemmen, James Demmel, and Kathy Yelick
PDF (1.2M)
Talk slides:PDF (3.9M)
- Paper: Auto-tuning the 27-point stencil for multicore
(iWAPT2009: The Fourth International Workshop on Automatic Performance Tuning, October 2009)
Kaushik Datta, Samuel Williams, Vasily Volkov, Jonathan Carter, Leonid Oliker, John Shalf, and Katherine Yelick
PDF (464k)
Talk slides: PDF (5.7 MB)
- Paper: Communication-Optimal Parallel and Sequential
Cholesky Decomposition
(Symposium on
Parallelism in Algorithms and Architectures (SPAA 2009),
August 2009)
Grey Ballard, James Demmel, Olga Holtz, and Oded Schwartz
PDF (152k)
*Journal version published in SISC 2010
- Paper: A Generalized Framework for Auto-tuning Stencil Computations
(Cray User
Group Conference, Atlanta, GA, May 2009)
[Winner, Best Paper]
Shoaib Kamil, Cy Chan, Sam Williams, Leonid Oliker, John Shalf, Mark Howison, E. Wes Bethel, Prabhat
PDF (354k)
- Journal Paper: Communication Requirements and Interconnect Optimization
for High-End Scientific Applications
(IEEE Transactions on Parallel and Distributed
Systems (TPDS), March 2009)
Shoaib Kamil, Leonid Oliker, Ali Pinar, John Shalf
Preprint PDF (8467k)
- Paper: Optimizing Collective Communication on Multicores
(HotPar 2009
, Berkeley, CA, USA, March 2009)
Rajesh Nishtala and Katherine Yelick
Paper: PDF (400kB)
- Journal Paper: Optimization and Performance Modeling of Stencil
Computations on Modern Microprocessors
(SIAM Review, December 2008)
Kaushik Datta, Shoaib Kamil, Samuel Williams, Leonid Oliker, John
Shalf, and Katherine Yelick
PDF (2.8 MB)
- Paper: Benchmarking GPUs to Tune Dense Linear Algebra
(Supercomputing
2008, November 2008)
[Winner, Best Student Paper]
Vasily Volkov and James Demmel
PDF (648k)
- Paper: Communication Avoiding Gaussian Elimination
(Supercomputing 2008, November 2008)
Laura Grigori, James Demmel, and Hua Xiang
PDF (584k)
- Paper: Stencil Computation Optimization and
Auto-Tuning on State-of-the-Art Multicore Architectures
(Supercomputing 2008, November 2008)
Kaushik Datta, Mark Murphy, Vasily Volkov, Samuel Williams, Jonathan
Carter, Leonid Oliker, David Patterson, John Shalf, and Katherine Yelick
PDF (612k)
Talk slides: PPT (12.9 MB)
- Paper: Hybrid Electric/Photonic Networks for Scientific Applications on Tiled CMPs
(Workshop on High Performance Embedding Computing, August 2008)
Ankit Jain, Shoaib Kamil, Marghoob Mohiyuddin, John Shalf, and John D. Kubiatowicz
Abstract: PDF (282k)
Talk slides: PPT (5.1 MB)
- Masters Report: pOSKI: An Extensible Autotuning Framework
to Perform Optimized SpMVs on Multicore Architectures
Ankit Jain
PDF (5.3 MB)
- Tech report: LU, QR and Cholesky Factorizations using
Vector Capabilities of GPUs
(UCB/EECS-2008-49, May 2008)
Vasily Volkov and James Demmel
PDF (1.0 MB)
- Paper: Avoiding Communication in Sparse Matrix Computations
(IEEE International Parallel and
Distributed Processing Symposium, April 2008)
James Demmel, Mark Hoemmen, Marghoob Mohiyuddin, and Katherine Yelick
PDF (1 MB)
Talk slides: PDF (6.2
MB)
- Paper: Lattice Boltzmann Simulation Optimization on
Leading Multicore Platforms
(IEEE International Parallel and
Distributed Processing Symposium, April 2008)
[Winner, Best Paper for Applications track]
Samuel Williams, Jonathan Carter, Leonid Oliker, John Shalf, and
Katherine Yelick
PDF (560k)
Talk slides: PDF (10.4 MB)
| PPT (2.6 MB)
- Tech report: Using GPUs to Accelerate the Bisection
Algorithm for Finding Eigenvalues of Symmetric Tridiagonal Matrices
(UCB/EECS-2007-179, December 2007)
Vasily Volkov and James Demmel
PDF (1.8 MB)
- Paper: Optimization of Sparse Matrix-Vector Multiplication
on Emerging Multicore Platforms
(Supercomputing 2007, November 2007)
Samuel Williams, Leonid Oliker, Richard Vuduc, John Shalf, Katherine
Yelick, and James Demmel
PDF (438k)
Talk slides: PDF (6.4 MB)
| PPT (2.5 MB)
- Tech report: Avoiding Communication in Computing Krylov Subspaces
(UCB/EECS-2007-123, October 2007)
James Demmel, Mark Hoemmen, Marghoob Mohiyuddin, and Katherine Yelick
PDF
(34.9 MB)
- Journal Paper: Scientific Computing Kernels on the Cell Processor
(International Journal of Parallel Programming, April 2007)
Samuel Williams, John Shalf, Leonid Oliker, Shoaib Kamil, Parry
Husbands, and Katherine Yelick
PDF (376k)
- Journal Paper: When Cache Blocking Sparse Matrix Vector Multiply Works and Why
(Applicable Algebra in Engineering, Communication and Computing, March 2007)
Rajesh Nishtala, Richard W. Vuduc, James W. Demmel, and Katherine Yelick
PDF (390k)
- Paper: Benchmarking Sparse Matrix-Vector Multiply in Five Minutes
(SPEC Benchmark Workshop 2007, Austin, TX, January 2007)
Hormozd Gahvari, Mark Hoemmen, James Demmel, Katherine Yelick
PDF (1 MB)
Talk slides: PPT (6.4 MB)
- Master's Thesis: Benchmarking Sparse Matrix-Vector Multiply
(Computer Science Division, U.C. Berkeley, December 2006)
Hormozd Gahvari
PDF (11.5 MB)
- Paper: Implicit and Explict Optimizations for Stencil
Computations
(Memory Systems Performance and Correctness, San Jose, California, USA, October 2006)
Shoaib Kamil, Kaushik Datta, Samuel Williams, Leonid Oliker, John
Shalf, and Katherine Yelick
PDF (604k)
Talk slides: PDF (3.2 MB)
- Paper: The Potential of the Cell Processor for Scientific
Computing
(Computing Frontiers 2006, Ischia, Italy, May 2006)
Samuel Williams, John Shalf, Leonid Oliker, Shoaib Kamil, Parry
Husbands, and Katherine Yelick
PDF (216k)
- Paper: Fast sparse matrix-vector multiplication by exploiting variable blocks
(Proceedings of the International Conference on High-Performance
Computing and Communications, Sorrento, Italy, September 2005)
Richard Vuduc and Hyun-Jin Moon.
PDF (322k)
- Paper: OSKI: A library of automatically tuned sparse matrix kernels
(Proceedings of SciDAC 2005, Journal of Physics: Conference Series, June 2005)
Richard Vuduc, James Demmel, and Katherine Yelick.
PDF (190k)
- Paper: Self-Adapting Linear Algebra Algorithms and Software
(Proceedings of the IEEE, Special
Issue on Program Generation, Optimization, and Adaptation,
93(2), February 2005)
James Demmel, Jack Dongarra, Victor Eijkhout, Erika Fuentes, Antoine
Petitet, Richard Vuduc, R. Clint Whaley, and Katherine Yelick.
PDF (600k)
- Paper: Performance Models for Evaluation and Automatic
Tuning of Symmetric Sparse Matrix-Vector Multiply
(International Conference on Parallel Processing, Montreal,
Quebec, Canada, August 2004)
[Winner, Best Paper Award]
Benjamin C. Lee, Richard Vuduc, James Demmel, and Katherine Yelick.
PDF (178k) | Gzip'd PostScript (204k)
Talk slides: PDF (540k)
- Paper: Toward automatic performance tuning of matrix
triple products based on matrix structure
(PARA'04 Workshop on State-of-the-art in Scientific Computing, Copenhagen, Denmark, June 2004.)
Eun-Jin Im, Ismail Bustany, Cleve Ashcraft, James Demmel, and Katherine Yelick.
- Tech Report: Performance Modeling and Analysis of Cache
Blocking in Sparse Matrix Vector Multiply
(UCB/CSD-04-1335, June 2004)
Rajesh Nishtala, Richard W. Vuduc, James W. Demmel, and Katherine A. Yelick
PDF (~8MB)
- Paper: SPARSITY: An Optimization Framework for Sparse Matrix Kernels
(International Journal of High Performance Computing Applications, 18 (1), pp. 135-158, February 2004)
Eun-Jin Im, Katherine A. Yelick, and Richard Vuduc.
PDF (1.1M)
| Gzip'd PostScript (1.2M)
- Paper: Statistical Models for Empirical Search-Based Performance Tuning
(International Journal of High Performance Computing Applications, 18 (1), pp. 65-94, February 2004)
Richard Vuduc, James W. Demmel, and Jeff A. Bilmes.
PDF (950k)
| Gzip'd PostScript (983k)
- Ph.D. Thesis: Automatic Performance Tuning of Sparse Matrix Kernels
(Computer Science Division, U.C. Berkeley, December 2003)
Richard Vuduc.
PDF (7.6M)
- Tech report: Performance Optimizations and Bounds for
Sparse Symmetric Matrix-Multiple Vector Multiply
(UCB/CSD-03-1297, November 2003)
Benjamin C. Lee, Richard W. Vuduc, James W. Demmel, Katherine
A. Yelick, Michael de Lorimier, and Lijue Zhong.
PDF (867k) | Gzip'd PostScript (1.3M)
- Senior Thesis: Effects of Block Size on the Block Lanczos Algorithm
(Dept. of Mathematics, U.C. Berkeley, June 2003)
Christopher Hsu
MS Word (2.2 MB)
| PDF (273k)
- Paper: Memory Hierarchy Optimizations and Performance Bounds for Sparse ATA*x
(ICCS 2003: Workshop on Parallel Linear Algebra, Melbourne, Australia, June 2003)
Richard Vuduc, Attila Gyulassy, James W. Demmel, and Katherine A. Yelick.
Abstract
| PDF (328k)
| Gzip'd PostScript (91k)
Talk slides, PDF (735k)
| Talk slides, gzip'd PostScript, 4-up (138k)
Extended version:
U.C. Berkeley Technical Report UCB/CS-03-1232
- Paper: Performance Optimizations and Bounds for Sparse Matrix-Vector Multiply
(Proceedings of the IEEE/ACM Conference on Supercomputing, 2002, Baltimore, MD, USA, November 2002)
Richard Vuduc, James W. Demmel, Katherine A. Yelick, Shoaib Kamil,
Rajesh Nishtala, and Benjamin Lee.
Abstract
| PDF (834k)
| Gzip'd PostScript (2.7M)
Talk slides, PDF (1.0M)
| Talk slides, gzip'd PostScript, 4-up (159k)
- Paper: Automatic Performance Tuning and Analysis of Sparse Triangular Solve
(ICS 2002: Workshop on Performance Optimization via High-Level Languages and Libraries, New York, NY, USA, June 2002)
Richard Vuduc, Shoaib Kamil, Jen Hsu, Rajesh Nishtala, James
W. Demmel, and Katherine A. Yelick.
Abstract
| PDF (548k)
| PostScript (1.2M)
Talk Slides, PDF (681k)
- Paper: Optimizing Sparse Matrix-Vector Multiplication for Register Reuse
Eun-jin Im and Katherine A. Yelick.
International Conference on Computational Science, San Francisco, California, May 2001.
PDF (164k)
Gzip'd PostScript (132k)
- Paper: Statistical Models for Automatic Performance Tuning
Richard Vuduc, James Demmel, Jeff Bilmes.
International Conference on Computational Science,
San Francisco, CA, USA, May 2001.
PDF (410k)
| Gzip'd PostScript (163k)
| Talk Slides, PDF (685k)
Writing in preparation:
- Tech report: Matrix Splitting and Reordering for Sparse Matrix-Vector Multiply
Hyun Jin Moon, Richard Vuduc, James W. Demmel, Katherine A. Yelick.
UCB Technical Report, 2003. (in preparation)
Abstract (DRAFT)
(Talks delivered in conjunction with conference papers appear
under Publications.)
Year: 2008
| 2005
| 2004
| 2003
| 2002
- Talks: Microsoft/Intel Visit to ParLab
Multiple Authors.
(Berkeley, California, USA, April 28-29, 2008)
Link
to Talks
- Talk: Avoiding Communication in Linear Algebra
James Demmel.
(SIAM PP 2008,
Atlanta, Georgia, USA, March 12-14, 2008)
Powerpoint (940k) | PDF (1.7MB)
- Talk: Bandwidth Avoiding Stencil Computations
Kaushik Datta, Sam Williams, James Demmel, Katherine Yelick.
(SIAM PP 2008, Atlanta, Georgia, USA,
March 12-14, 2008)
Powerpoint (2.45MB) | PDF (3.05MB)
- Talk: Fast Implementations of the Akx Kernel
Marghoob Mohiyuddin, Mark Hoemmen, James Demmel, Katherine Yelick.
(SIAM PP 2008, Atlanta, Georgia, USA,
March 12-14, 2008)
PDF (9.3MB)
- Talk: Communication-avoiding Krylov subspace methods
Mark Hoemmen.
(SIAM PP 2008, Atlanta, Georgia, USA,
March 12-14, 2008)
PDF (952k)
- Talk: The Future of Numerical Linear Algebra Libraries: Automatic Tuning of Sparse Matrix Codes and the Next LAPACK and ScaLAPACK
(SciDAC 2005 Meeting, San Francisco, California, USA, June 2005)
PowerPoint (305k)
- Talk: OSKI: An automatically tuned library of sparse matrix kernels
(SIAM CSE 2005, Orlando, Florida, USA, February 2005)
Richard Vuduc, James Demmel, Katherine Yelick.
PowerPoint
| PDF
- Talk: When Cache Blocking Sparse Matrix Multiply Works and Why
(PARA'04 Workshop on State-of-the-art in Scientific Computing, Copenhagen, Denmark, June 2004)
Rajesh Nishtala, Richard Vuduc, James Demmel, Katherine Yelick.
PDF (147k)
| Gzip'd PostScript (138k) | Talk Slides: MS PPT (3MB)
- Talk: Adaptable benchmarks for register blocked sparse matrix-vector multiplication, Mark Hoemmen, Matrix Computations Seminar at U.C. Berkeley, May 5, 2004.
PowerPoint (420k)
| PDF (420k)
| Link to Software
- Talk: Performance Optimizations and Bounds for Symmetric Sparse Matrix-Multiple Vector Multiply
SIAM Parallel Processing Meeting, San Francisco, California, USA, March 2004.
PowerPoint (319k)
| PDF (331k)
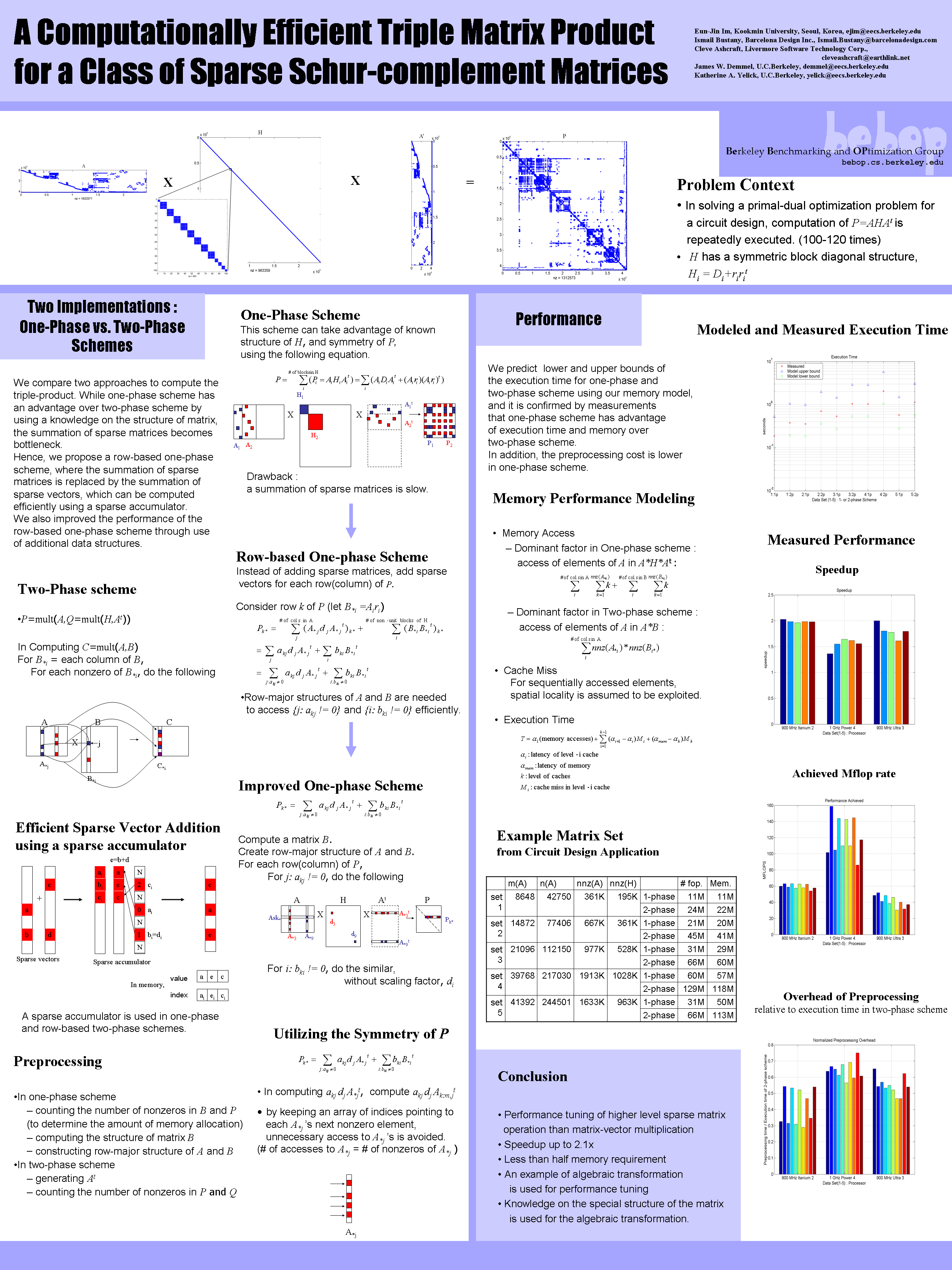
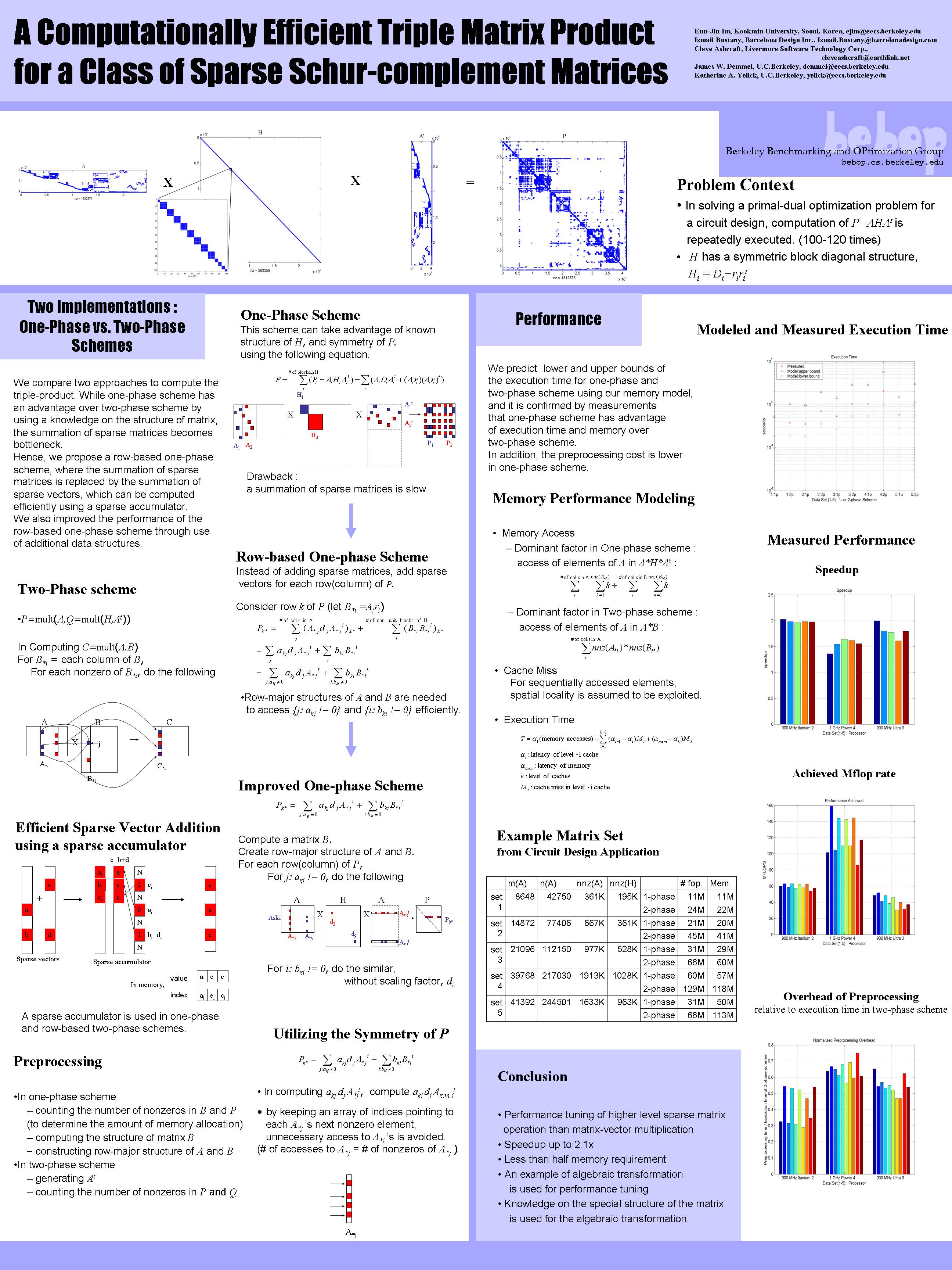
- Poster: A Computationally Efficient Triple Matrix Product for a Class of Sparse Schur-Complement Matrices
SIAM Parallel Processing Meeting, San Francisco, California, USA, March 2004.
PowerPoint (678k)
| PDF (177k)
| PNG (504k)
| GIF (436k)
| JPEG (985k)
- Poster: Automatic Tuning of Collective Communications in MPI
An overview of the Probabilistic Algorithm Selection System (PASS) for finding and choosing the best implementation of a given MPI collective operation on a given hardware platform.
PowerPoint (5.3M)
| PDF (118k)
Full report: PDF (1.9 MB)
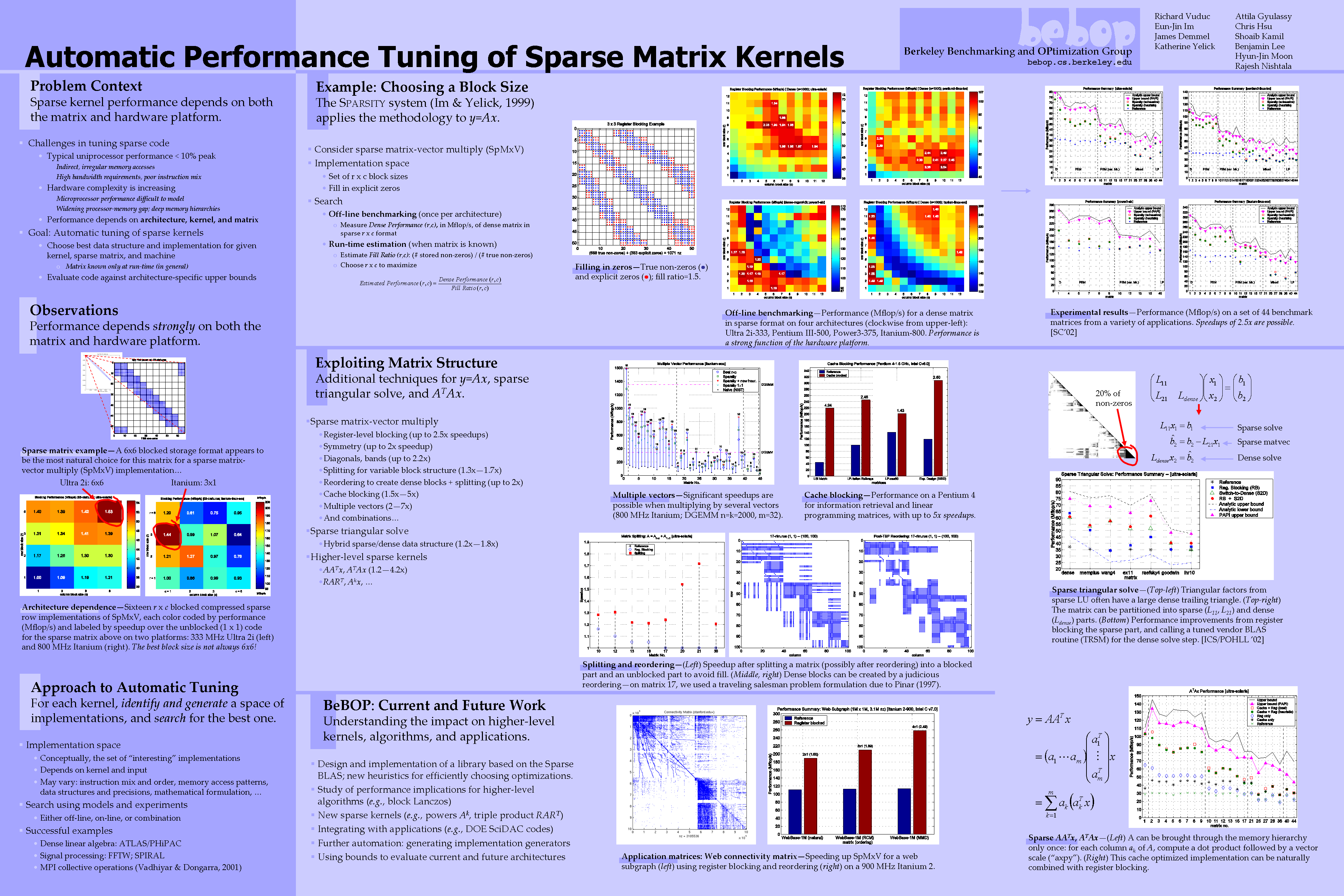
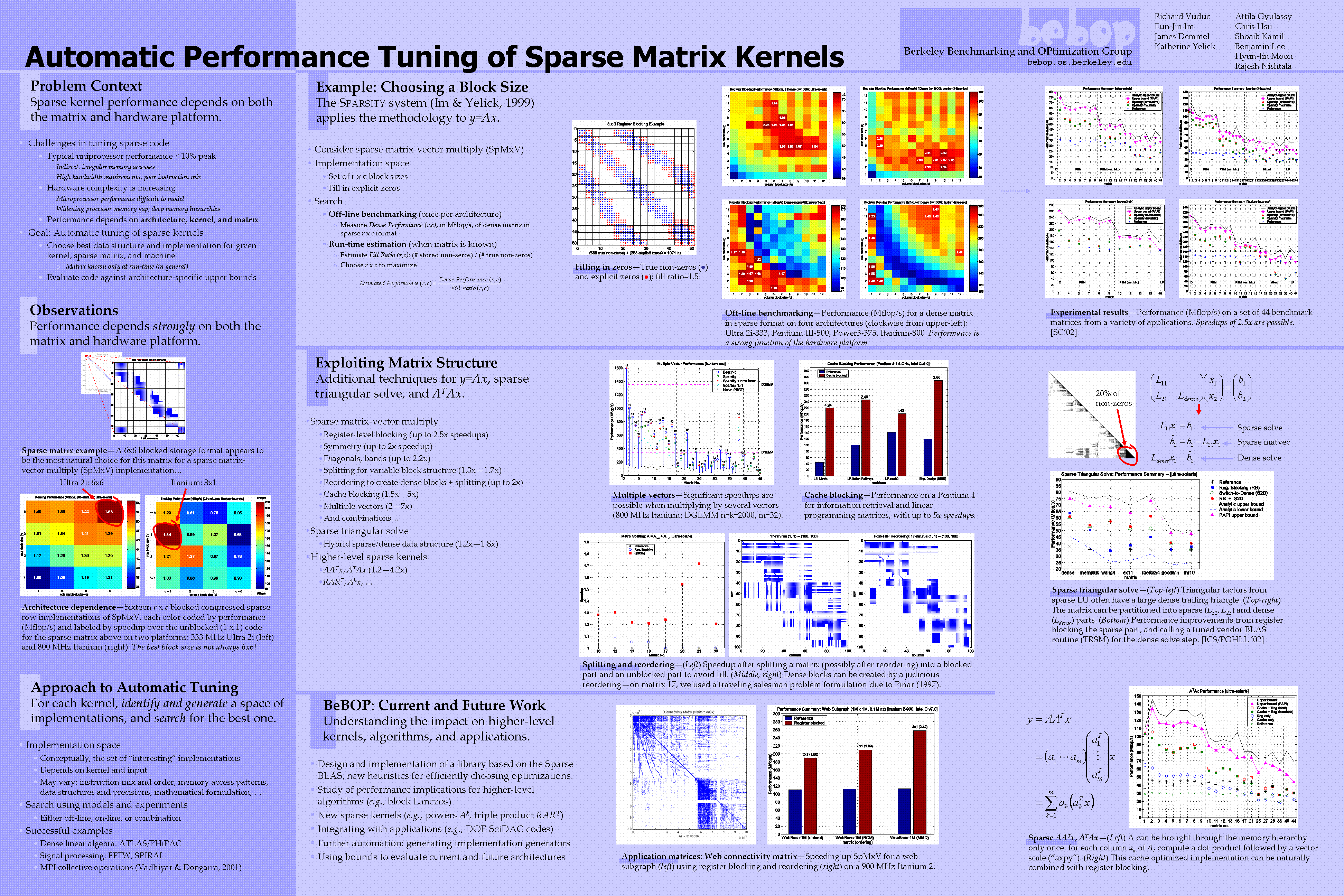
- Poster: Automatic Performance Tuning of Sparse Matrix Kernels
This poster, shown at the Berkeley-Stanford CS Day
(2002,
2003),
Bay Area Scientific Computing Day (2002), and the SIAM CSE 2003 Meeting,
summarizes our overall approach to tuning a number of
sparse matrix kernels, including matrix-vector
multiply (non-symmetric and symmetric),
triangular solve, and multiplication by
ATA.
PowerPoint (1.7 MB)
| PDF (617k)
| PNG (520 kB)
| GIF (715 kB)
| JPEG (1.5 MB)
- Talk: Automatic Performance Tuning of Sparse Matrix Kernels
Presentation of recent work to Intel, with a discussion
of ideas related to acceleration of the Google PageRank
algorithm. (24 Jan 2003)
PowerPoint (806 kB)
| PDF (830k)
Google matrix pics, PowerPoint (142 kB)
| PDF (139k)
- Talk: Automatic Performance Tuning of Linear Algebra Kernels
This presentation, given at the
TOPS-SciDAC
kick-off meeting (25 Jan 2002), describes recent results
performance tuning of sparse linear algebra kernels.
PowerPoint (1.5 MB)
| PDF (2.7 MB)
Current Local Activities
Prior Projects
- XBLAS: Extended and Mixed-Precision BLAS
- Sparsity: A Toolkit for Optimizing Sparse Matrix-Vector Multiply
- IRAM: Intelligent RAM Project
- Titanium: High-Performance Java Compiler
- PHiPAC:
An Automatic Tuning System for Matrix Multiply
External Collaborations
This research was supported in part by
the National Science Foundation under
NSF Cooperative Agreement No. ACI-9813362,
NSF Cooperative Agreement No. ACI-9619020,
the Department of Energy under
DOE Grant No. DE-FC02-01ER25478,
and a gift from Intel.
The information presented here does not necessarily reflect
the position or the policy of the Government and no
official endorsement should be inferred.
Standard disclaimer: Publications are presented to ensure timely
dissemination of scholarly and technical work. Copyright and all
rights therein are retained by authors or by other copyright
holders. All persons copying this information are expected to
adhere to the terms and constraints invoked by each author's
copyright. In most cases, these works may not be reposted without
the explicit permission of the copyright holder.
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}